Redis 核心概念、数据结构与高可用架构详解
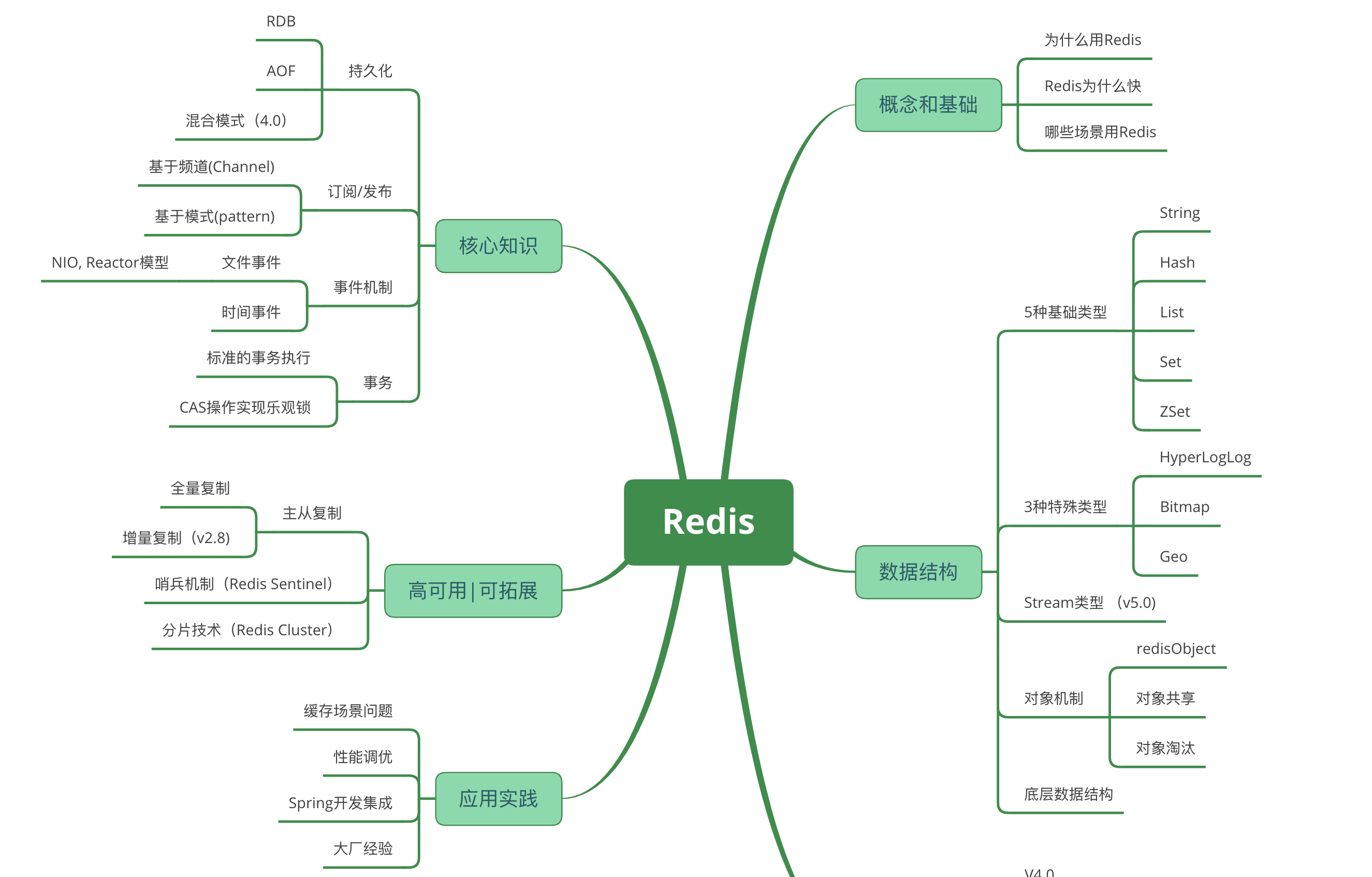
Redis 是后端系统里最常见的基础组件之一:它既可以做缓存,也可以做分布式锁、排行榜、限流计数器、延迟队列、会话存储,还可以通过主从复制、Sentinel 和 Cluster 构建高可用架构。
这篇文章从 Redis 的核心概念开始,系统梳理常用数据类型、底层数据结构、过期与淘汰、持久化、事务、主从复制、哨兵、集群、缓存问题和分布式锁,适合作为学习笔记、面试复习材料,也可以作为生产架构设计时的检查清单。
Redis 是什么
Redis(Remote Dictionary Server)是一个以内存为主的键值型数据结构服务器。它不是简单的 key-value 字符串缓存,而是提供了多种高层数据结构,并围绕这些结构提供原子命令、过期时间、发布订阅、Lua 脚本、持久化、复制与集群能力。
Redis 常见用途包括:
- 热点数据缓存:缓存用户、商品、配置、字典等高频读取数据。
- 计数器与限流:基于
INCR、EXPIRE或 Lua 实现访问频率控制。 - 分布式锁:基于
SET key value NX PX实现互斥控制。 - 排行榜:基于 ZSet 的 score 排序能力实现积分榜、热榜。
- 消息与事件流:基于 List、Pub/Sub 或 Stream 实现轻量队列。
- 地理位置查询:基于 Geo 命令实现附近的人、门店距离计算。
- 去重与统计:基于 Set、Bitmap、HyperLogLog 做集合运算和近似计数。
Redis 为什么快
Redis 的高性能来自多个因素共同作用,不应简单理解为“因为单线程所以快”。
1. 以内存访问为主
Redis 将主要数据放在内存中,避免了传统数据库频繁磁盘随机 I/O 的开销。即使开启 RDB 或 AOF 持久化,普通命令的读写路径仍主要围绕内存结构进行。
2. 高效的数据结构
Redis 针对不同对象大小和访问模式设计了多种内部编码,例如 SDS、dict、quicklist、listpack、skiplist、intset、rax 等。小对象优先使用紧凑编码节省内存,大对象再切换到更适合查询或更新的数据结构。
3. 单线程命令执行模型
Redis 的命令执行主体长期采用单线程事件循环,天然避免了多线程共享数据结构带来的锁竞争和上下文切换问题。需要注意的是:
- “单线程”主要指命令执行路径,而不是 Redis 整个进程只有一个线程。
- 后台持久化、异步删除、复制相关任务可能由后台线程或子进程处理。
- Redis 6 引入 I/O 多线程,主要用于网络读写处理,命令执行本身仍保持单线程语义。
4. I/O 多路复用
Redis 使用事件驱动模型,通过 epoll、kqueue 等 I/O 多路复用机制同时处理大量客户端连接,避免为每个连接创建独立线程。
5. 简洁的 RESP 协议
Redis 使用 RESP(Redis Serialization Protocol)协议,协议格式简单,解析成本低,适合高吞吐命令交互。
Redis 数据类型
Redis 官方文档将 Redis 定位为 data structure server。常见数据类型不仅包括传统五大基础类型,也包括 Stream、Bitmap、Bitfield、HyperLogLog、Geo 等能力。
String
String 是 Redis 最基础的类型,可以保存字符串、数字、二进制内容。
常见场景:
- 缓存 JSON 字符串。
- 计数器:
INCR、DECR。 - 分布式锁:
SET lock_key request_id NX PX 30000。 - Bitmap/Bitfield 的底层也基于 String。
常用命令:
SET user:1 "Ryan"
GET user:1
INCR article:100:views
SETEX verify:phone:13800000000 300 123456
Hash
Hash 适合保存对象型数据,由 field-value 组成。
常见场景:
- 用户信息、商品信息等对象缓存。
- 局部字段更新,避免每次覆盖整个 JSON。
HSET user:1 name Ryan age 18
HGET user:1 name
HGETALL user:1
HINCRBY user:1 login_count 1
List
List 是按插入顺序排列的字符串列表,适合队列、栈、时间线等场景。
LPUSH queue:email msg1
RPOP queue:email
BRPOP queue:email 5
需要注意:如果要做可靠消息队列,List 需要额外处理消息确认、失败重试和死信问题;更推荐考虑 Stream 或专业消息队列。
Set
Set 是无序去重集合,支持交集、并集、差集。
常见场景:
- 标签系统。
- 点赞用户集合。
- 好友关系与共同关注。
- 抽奖去重。
SADD article:1:likes user:1 user:2
SISMEMBER article:1:likes user:1
SINTER user:1:follows user:2:follows
Sorted Set / ZSet
ZSet 是带 score 的有序集合,适合排行榜、延迟任务、权重排序。
ZADD rank:score 100 user:1 80 user:2
ZREVRANGE rank:score 0 9 WITHSCORES
ZRANGEBYSCORE delay:queue 0 1893456000000
Stream
Stream 是 Redis 5.0 引入的追加日志型数据结构,支持消息 ID、消费者组、ACK、Pending List,适合轻量事件流场景。
XADD order:events * orderId 1001 status created
XGROUP CREATE order:events group-a 0 MKSTREAM
XREADGROUP GROUP group-a consumer-1 COUNT 10 STREAMS order:events >
XACK order:events group-a 1710000000000-0
Stream 比 List 更适合需要消费者组、消息确认和消息回溯的场景,但如果系统对顺序、事务、堆积、重试、可观测性要求很高,仍应评估 RocketMQ、Kafka 等专用消息系统。
Bitmap 与 Bitfield
Bitmap 不是独立底层类型,而是基于 String 的位操作能力,适合表示大量二值状态。
常见场景:
- 用户签到。
- 日活统计。
- 布尔状态标记。
SETBIT user:sign:202606 28 1
GETBIT user:sign:202606 28
BITCOUNT user:sign:202606
Bitfield 可以在字符串中按位宽维护多个整数计数器,适合更精细的位级编码。
HyperLogLog
HyperLogLog 用于大规模基数估算,典型场景是 UV 统计。它牺牲少量精确性换取很低的内存占用。
PFADD uv:2026-06-29 user:1 user:2 user:3
PFCOUNT uv:2026-06-29
Geo
Geo 主要用于地理位置写入、距离计算和范围查询。需要注意 Geo 能力通常基于 Sorted Set 编码地理位置,而不是完全独立的底层类型。
GEOADD shop:geo 113.2644 23.1291 shop:1
GEODIST shop:geo shop:1 shop:2 km
GEOSEARCH shop:geo FROMLONLAT 113.26 23.13 BYRADIUS 5 km
Redis 底层数据结构
理解 Redis 的底层结构,有助于解释为什么某些命令复杂度不同,也有助于做内存优化。
redisObject
Redis 内部对象一般会包含:
type:对象类型,如 string、list、hash、set、zset、stream。encoding:底层编码,如 int、embstr、raw、listpack、hashtable、quicklist、skiplist 等。ptr:指向实际数据结构。lru/lfu:记录访问时间或访问频率,用于淘汰策略。refcount:引用计数。
同一个逻辑类型在不同数据规模下可能采用不同编码。例如 Hash 在元素较少时可以使用 listpack,数据变大后会转为 hashtable。
SDS
SDS(Simple Dynamic String)是 Redis 的动态字符串结构。相比 C 字符串,它通常会记录长度和已分配空间,支持二进制安全内容,也便于扩容。
优势:
- 获取长度复杂度低。
- 二进制安全,可以保存
\0。 - 扩容时减少频繁内存分配。
dict
dict 是 Redis 字典结构,广泛用于:
- Redis 全局 key 空间。
- Hash 的 hashtable 编码。
- Set 的 hashtable 编码。
- ZSet 中 member 到 score 的映射。
Redis 字典扩容时会进行渐进式 rehash,避免一次性迁移大量数据导致长时间阻塞。
listpack
listpack 是一种紧凑连续内存编码,用于替代早期 ziplist 的许多使用场景。它适合小对象、小集合,优点是内存利用率高,缺点是元素过多时插入、删除和查找成本会上升。
quicklist
List 的主要实现是 quicklist,可以理解为双向链表加紧凑列表节点的组合:
- 宏观上是链表,便于两端插入和删除。
- 微观上每个节点内部使用紧凑编码,减少指针开销。
在较新 Redis 版本中,quicklist 节点内部更多使用 listpack,而不是旧资料中常见的 ziplist。
intset
intset 是整数集合编码。当 Set 中元素都是整数且数量较少时,Redis 可以使用 intset 节省内存;当元素类型或数量超过阈值后,会转换为 hashtable。
skiplist
skiplist(跳表)常用于 ZSet 大对象场景,配合 dict 同时满足:
- 按 member 快速查 score。
- 按 score 范围查询和排序遍历。
rax
rax 是 radix tree 的一种实现,Redis Stream 内部会使用 radix tree 组织消息 ID,并结合 listpack 存储消息内容。
过期键删除与内存淘汰
这两个概念容易混淆,需要拆开理解。
过期键删除策略
Redis 支持给 key 设置 TTL:
SETEX verify:code:13800000000 300 123456
EXPIRE user:1 3600
TTL user:1
过期键删除主要包括:
- 惰性删除:访问 key 时发现已过期,再删除。
- 定期删除:后台周期性抽样检查过期 key 并删除。
仅靠惰性删除会导致冷数据长期占用内存;仅靠全量定期扫描成本太高,因此 Redis 使用两者结合。
内存淘汰策略
当配置了 maxmemory 且内存达到上限时,Redis 会根据 maxmemory-policy 选择淘汰策略。常见策略包括:
noeviction:不淘汰,写命令返回错误。allkeys-lru:在所有 key 中按 LRU 近似淘汰。volatile-lru:只在设置了过期时间的 key 中按 LRU 近似淘汰。allkeys-lfu:在所有 key 中按 LFU 近似淘汰。volatile-lfu:只在设置了过期时间的 key 中按 LFU 近似淘汰。allkeys-random:在所有 key 中随机淘汰。volatile-random:只在设置了过期时间的 key 中随机淘汰。volatile-ttl:优先淘汰 TTL 更短的 key。
实践建议:
- 纯缓存场景通常考虑
allkeys-lru或allkeys-lfu。 - 业务明确区分缓存 key 和非缓存 key 时,可以考虑
volatile-*,但必须确保缓存 key 都设置 TTL。 - 不希望 Redis 自动丢数据时使用
noeviction,并通过监控提前扩容或清理。
持久化:RDB、AOF 与混合持久化
Redis 是内存数据库,但可以通过持久化降低宕机后的数据丢失风险。
RDB
RDB 是快照持久化,会在某个时间点生成数据快照文件。
优点:
- 文件紧凑,适合备份和灾难恢复。
- 恢复速度通常较快。
- 对主进程影响相对可控。
缺点:
- 两次快照之间的数据可能丢失。
- fork 子进程时可能带来内存和延迟压力。
AOF
AOF 会记录写命令日志,Redis 重启时通过重放 AOF 恢复数据。
常见 appendfsync 策略:
always:每次写都刷盘,安全性高但性能差。everysec:通常每秒刷盘一次,性能和可靠性折中,生产常用。no:交给操作系统决定刷盘时机,性能好但风险更高。
AOF 文件会随着写入增长,因此需要 rewrite 机制对日志进行重写压缩。
混合持久化
Redis 支持 RDB + AOF 混合持久化:AOF 重写后的文件前半部分可以是 RDB 格式快照,后半部分再追加增量 AOF。这样兼顾恢复速度和数据安全性。
生产建议:
- 缓存可重建:可以弱化持久化,重点关注命中率和雪崩保护。
- 数据不可轻易丢失:开启 AOF everysec,并配合主从、备份和监控。
- 大实例:关注 fork 耗时、写放大、AOF rewrite、磁盘 I/O 和延迟尖刺。
事务、Lua 与原子性
Redis 事务由 MULTI、EXEC、DISCARD、WATCH 组成。
MULTI
INCR account:1
INCR account:2
EXEC
Redis 事务提供的核心保证是:队列中的命令会按顺序连续执行,中间不会插入其他客户端命令。但它不是关系型数据库意义上的完整 ACID 事务,尤其需要注意:
- Redis 事务不支持自动 rollback。
EXEC执行阶段某条命令运行错误,不会回滚其他已执行命令。WATCH提供乐观锁能力,被监控 key 发生变化时,EXEC会失败。
对于需要“读取、判断、写入”整体原子执行的逻辑,可以使用 Lua 脚本:
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end
Lua 脚本在 Redis 中原子执行,常用于释放分布式锁、限流、库存扣减等场景。但脚本不能执行过久,否则会阻塞 Redis 主线程。
主从复制
Redis 主从复制用于读扩展、故障恢复和高可用基础建设。
复制流程
典型流程如下:
- 从节点连接主节点,发送复制请求。
- 主节点生成复制快照,并将期间新增写命令写入复制缓冲区。
- 从节点加载快照。
- 主节点继续向从节点发送增量命令。
- 复制链路正常时保持命令流同步。
Redis 支持部分重同步,当复制连接短暂中断且复制积压缓冲区仍保留所需偏移量时,从节点可以只补增量数据,避免全量同步。
复制延迟
复制是异步的,因此主从之间可能存在延迟。生产上需要关注:
- 从库读到旧数据。
- 主库故障时最近写入可能尚未复制。
- 大 key、慢查询、网络抖动会扩大复制延迟。
实践建议:
- 强一致读不要随意走从库。
- 监控
master_link_status、复制偏移量和复制延迟。 - 避免大 key 和阻塞命令影响复制链路。
Sentinel 高可用
Sentinel 用于监控 Redis 主从实例,并在主节点故障时自动完成故障转移。
Sentinel 的核心职责:
- 监控:定期检查主从节点是否可达。
- 通知:发现异常时可以触发告警。
- 自动故障转移:主节点不可用时,选举一个从节点提升为新主节点。
- 配置提供者:客户端可以通过 Sentinel 获取当前主节点地址。
主观下线与客观下线
- 主观下线(SDOWN):单个 Sentinel 认为某实例不可达。
- 客观下线(ODOWN):多个 Sentinel 达成多数判断,认为主节点确实不可用。
故障转移流程
简化流程:
- Sentinel 发现主节点疑似不可用。
- 多个 Sentinel 投票确认客观下线。
- Sentinel 之间选出一个 leader 执行故障转移。
- 从节点中选择一个最合适的节点提升为主节点。
- 其他从节点重新复制新主节点。
- 客户端通过 Sentinel 感知新主节点地址。
注意:Sentinel 的选举和多数派机制容易让人联想到 Raft,但不要简单说 Sentinel “使用 Raft”。更准确的说法是:Sentinel 使用投票和多数派机制协调故障转移。
Sentinel 适用场景
Sentinel 适合单主多从、高可用优先、数据规模单机可承载的场景。如果数据容量或写入吞吐超过单机上限,则需要考虑 Redis Cluster。
Redis Cluster 集群
Redis Cluster 用于数据分片和高可用。它将整个 key 空间划分为 16384 个 hash slot,每个主节点负责其中一部分槽位。
槽位计算公式:
slot = CRC16(key) mod 16384
注意是对 16384 取模,而不是 16383。
Hash Tag
如果希望多个 key 落到同一个槽,可以使用 hash tag:
order:{1001}:detail
order:{1001}:items
Redis Cluster 只会对 {} 中的内容计算槽位,因此上述两个 key 会落在同一个 slot,便于执行部分多 key 操作。
MOVED 与 ASK
客户端访问错误节点时,Cluster 会返回重定向:
MOVED:槽位已经稳定迁移到其他节点,客户端应更新槽位缓存。ASK:槽位正在迁移中,客户端临时访问目标节点。
生产上应使用支持 Cluster 的客户端,例如 Lettuce、Jedis、Redisson 等,而不是手动处理重定向。
Cluster 的限制
- 多 key 操作要求 key 在同一个 slot。
- 跨 slot 事务、Lua、多 key 命令受限制。
- 扩缩容和 slot 迁移会增加运维复杂度。
- Cluster 不等于强一致系统,故障切换期间仍可能有短暂不可用或数据丢失窗口。
Sentinel 与 Cluster 如何选择
| 方案 | 解决的问题 | 适用场景 |
|---|---|---|
| 主从复制 | 读扩展、数据副本 | 基础能力,通常配合 Sentinel 或 Cluster |
| Sentinel | 单主故障自动转移 | 单机容量足够,但要求高可用 |
| Cluster | 分片扩容 + 高可用 | 单机容量或吞吐不足,需要水平扩展 |
缓存常见问题
缓存穿透
缓存穿透指请求查询的数据在缓存和数据库中都不存在,导致请求持续打到数据库。
解决方案:
- 对空结果进行短 TTL 缓存。
- 使用布隆过滤器拦截明显不存在的 key。
- 做参数校验和风控限流。
缓存击穿
缓存击穿指某个热点 key 过期瞬间,大量请求同时打到数据库。
解决方案:
- 热点 key 不过期或逻辑过期。
- 互斥锁重建缓存。
- 后台异步刷新热点数据。
缓存雪崩
缓存雪崩指大量 key 同时失效,或 Redis 整体不可用,导致数据库瞬间承压。
解决方案:
- TTL 增加随机抖动。
- 热点数据分批过期。
- 多级缓存。
- Redis 高可用和限流降级。
缓存与数据库一致性
常见策略是 Cache Aside:
- 读请求先查缓存,未命中再查数据库并写入缓存。
- 写请求先更新数据库,再删除缓存。
为什么通常是删除缓存而不是更新缓存?
- 删除缓存可以让下一次读重新从数据库加载最新值。
- 更新缓存容易受到并发写顺序影响,出现旧值覆盖新值。
如果一致性要求更高,可以结合延迟双删、消息队列、binlog 订阅、版本号、逻辑过期等方案,但要结合业务接受的数据延迟来设计。
分布式锁
Redis 分布式锁的基本实现:
SET lock:order:1001 request-id-123 NX PX 30000
含义:
NX:只有 key 不存在时才设置成功。PX 30000:设置 30 秒过期时间,避免客户端宕机后锁无法释放。request-id-123:锁持有者标识,用于防止误删他人锁。
释放锁时应使用 Lua 脚本保证“判断持有者 + 删除”原子性:
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end
需要注意:
- 锁过期时间要大于业务最大执行时间,必要时引入 watchdog 自动续期。
- 加锁成功只代表获得 Redis 层面的互斥,不代表业务一定成功。
- 主从异步复制下,主节点宕机可能导致锁数据未复制到新主,存在极端并发风险。
- RedLock 适合讨论多 Redis 实例下的锁可靠性,但实现复杂且有争议。强一致场景应评估数据库唯一约束、ZooKeeper、etcd 等方案。
客户端选择上,不能简单说“官方推荐 Redisson”。更准确的说法是:
- Lettuce:基于 Netty,支持同步、异步、响应式,Spring Data Redis 默认常见选择。
- Jedis:API 直接,使用广泛,适合偏简单的同步调用场景。
- Redisson:提供分布式锁、集合、限流器等更高层抽象,适合需要分布式对象能力的场景。
生产实践检查清单
Key 设计
- 使用统一前缀:
业务:模块:实体:id。 - 避免过长 key,控制内存浪费。
- 使用 hash tag 时明确同槽目的,不要滥用。
- 给缓存 key 设置合理 TTL,并增加随机抖动。
Big Key 与 Hot Key
Big Key 问题:单个 key 过大,导致网络传输、删除、复制、迁移都变慢。
治理方式:
- 拆分大 Hash、Set、ZSet。
- 使用
UNLINK异步删除大 key。 - 控制 value 大小,避免缓存超大 JSON。
Hot Key 问题:某个 key 被极高频访问,导致单节点或单线程成为瓶颈。
治理方式:
- 本地缓存或多级缓存。
- 热点 key 分片。
- 读写隔离和限流。
- 提前识别热点并预热。
慢查询与阻塞命令
避免在线执行高风险命令:
KEYS *- 大范围
HGETALL、SMEMBERS、ZRANGE 0 -1 - 大 key 的同步
DEL - 复杂 Lua 长时间执行
替代方案:
- 使用
SCAN渐进扫描。 - 分页读取集合数据。
- 使用
UNLINK异步删除。 - 对 Lua 脚本设置复杂度边界。
监控指标
建议重点关注:
- QPS、延迟、慢查询。
- 内存使用、碎片率、淘汰次数。
- 命中率、过期 key 数、淘汰 key 数。
- 主从复制状态和复制延迟。
- AOF rewrite、RDB save、fork 耗时。
- 客户端连接数、阻塞客户端数。
- Cluster slot 状态、迁移状态、failover 事件。
总结
Redis 的核心价值不只是“快”,而是围绕内存数据结构提供了一整套高性能数据访问能力。学习 Redis 时可以按下面这条主线理解:
- 数据类型:String、Hash、List、Set、ZSet、Stream、Bitmap、HyperLogLog、Geo。
- 内部结构:SDS、dict、listpack、quicklist、intset、skiplist、rax。
- 内存治理:过期删除与 maxmemory 淘汰是两套机制。
- 可靠性:RDB、AOF、混合持久化分别解决不同级别的数据恢复问题。
- 高可用:主从复制解决副本,Sentinel 解决自动故障转移,Cluster 解决分片扩容。
- 生产问题:缓存穿透、击穿、雪崩、一致性、分布式锁、Big Key、Hot Key 都需要结合业务场景处理。
如果是面试复习,重点要能讲清楚:Redis 为什么快、数据类型和底层结构、过期删除和淘汰策略区别、事务为什么不等同于数据库事务、Sentinel 故障转移流程、Cluster 的 16384 槽和多 key 限制。