B+树原理与 MySQL InnoDB 索引机制解析
B+树原理与 MySQL InnoDB 索引机制解析
前言
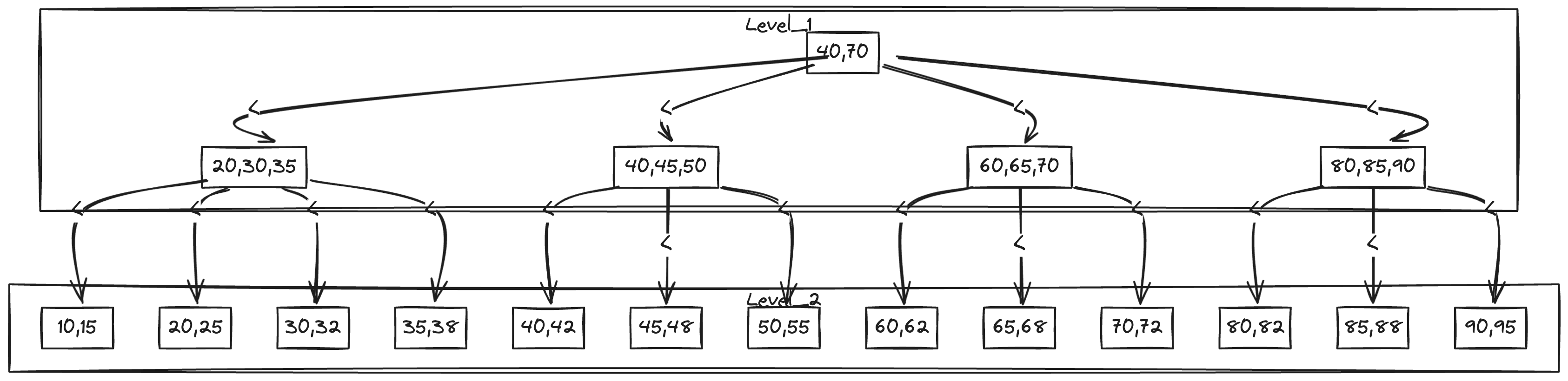
B+ 树是一种多叉平衡搜索树,广泛应用于数据库索引、文件系统和存储引擎中。相比二叉搜索树、红黑树或哈希表,B+ 树更适合以“页”为单位组织大量有序数据,尤其适合范围查询和磁盘 I/O 场景。
在 MySQL InnoDB 中,索引结构通常可以理解为 B+ 树:
- 主键索引通常是聚簇索引;
- 二级索引的叶子节点保存索引列和主键值;
- 查询可能发生回表;
- 覆盖索引可以避免回表;
- 联合索引遵循最左前缀原则;
- 自增主键通常更有利于减少页分裂和随机写入。
本文先介绍 B+ 树的基本原理,再结合 MySQL InnoDB 索引机制解释其在数据库中的实际应用。
1. B+树是什么
1.1 多叉平衡搜索树
B+ 树是一种多叉平衡搜索树。与二叉树相比,B+ 树的每个节点可以拥有多个子节点,因此在相同数据量下树高更低。
树高更低意味着:
- 从根节点定位到叶子节点经过的层数更少;
- 查询需要访问的页更少;
- 磁盘 I/O 次数更少;
- 更适合数据库和文件系统这类大规模数据场景。
1.2 内部节点与叶子节点
B+ 树主要包含两类节点:
| 节点类型 | 作用 |
|---|---|
| 内部节点 | 存储索引键和子节点指针,用于导航 |
| 叶子节点 | 存储最终数据或数据引用,并按键值有序排列 |
简化结构如下:
[根节点]
/ | \
[内部节点] [内部节点] [内部节点]
/ | \ | / \
[叶子] [叶子] [叶子] ... [叶子] [叶子]
1.3 叶子节点有序链表
B+ 树的叶子节点通常通过指针连接成有序链表。这个设计非常适合范围查询。
例如查询:
WHERE id BETWEEN 100 AND 200
数据库可以先通过 B+ 树定位到 id = 100 附近的叶子节点,然后沿着叶子节点链表顺序扫描,直到超过 200 为止。
1.4 B+树与 B 树的区别
B 树和 B+ 树都是平衡多路搜索树,但它们有几个关键差异:
| 对比项 | B 树 | B+ 树 |
|---|---|---|
| 数据存储位置 | 内部节点和叶子节点都可能存数据 | 通常只有叶子节点存数据或数据引用 |
| 范围查询 | 需要中序遍历多个层级 | 叶子节点链表顺序扫描更友好 |
| 节点扇出 | 内部节点存数据,能放的 key 较少 | 内部节点只存索引,能放更多 key |
| 树高 | 相对更高 | 通常更低 |
| 数据库索引适配 | 可以使用 | 更适合数据库页和范围查询 |
需要注意:B 树本身也是平衡树,并不会因为数据量小就“退化成链表”。B+ 树的优势主要在于内部节点更轻、扇出更高、范围扫描更友好。
2. 为什么 B+树适合数据库索引
2.1 树高低,减少磁盘 I/O
数据库通常以页为单位读取数据。一次索引查询大致需要从根节点一路访问到叶子节点。
如果 B+ 树高度较低,查询路径就短,访问的页也更少。内部节点只保存索引键和指针,可以容纳更多 key,使树的扇出更高,从而降低树高。
2.2 叶子节点有序,适合范围查询
B+ 树的叶子节点按 key 有序排列,并通过链表连接,非常适合:
BETWEEN>/<>=/<=- 前缀范围查询
ORDER BY- 部分
GROUP BY
MySQL 的 B-tree 索引可以用于 =, >, <, BETWEEN, IN 等查询条件。
2.3 更适合数据库页和缓存
B+ 树节点可以映射到数据库页。数据库可以缓存根节点、内部节点和热点叶子节点,减少磁盘访问。
相比红黑树等二叉树,B+ 树每个节点包含更多 key,更适合页式存储;相比哈希表,B+ 树天然支持有序扫描和范围查询。
2.4 物理连续性不能绝对化
很多文章会说“B+ 树叶子节点在磁盘上连续存储”。更严谨的说法是:
B+ 树叶子节点在逻辑上有序,并通过链表相连。数据库以页为单位组织索引数据,范围查询可以沿叶子节点顺序扫描,从而比随机访问更友好。但物理磁盘上是否完全连续,取决于存储引擎、页分裂、写入顺序和文件系统状态。
3. InnoDB 中的 B+树索引
3.1 聚簇索引
在 InnoDB 中,表数据按照聚簇索引组织。通常情况下,主键索引就是聚簇索引。
聚簇索引的特点:
- 叶子节点保存完整行数据;
- 数据按主键顺序组织;
- 每张 InnoDB 表通常只有一个聚簇索引;
- 如果没有显式主键,InnoDB 会选择唯一非空索引或生成隐藏行 ID。
示例:
CREATE TABLE orders (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id BIGINT NOT NULL,
status VARCHAR(20) NOT NULL,
create_time DATETIME NOT NULL,
amount DECIMAL(10,2) NOT NULL
) ENGINE=InnoDB;
这里 id 是主键,InnoDB 会围绕主键构建聚簇索引,叶子节点保存完整行数据。
3.2 二级索引
除主键索引外,其他普通索引一般称为二级索引。
二级索引的叶子节点通常保存:
- 二级索引列值;
- 对应的主键值。
例如:
CREATE INDEX idx_user_id ON orders(user_id);
通过 idx_user_id 查询时,InnoDB 先在二级索引 B+ 树中找到对应的主键值,再根据主键值回到聚簇索引查询完整行。
3.3 回表
如果通过二级索引查到的字段不足以满足查询,需要再根据主键到聚簇索引中查询完整行,这个过程通常称为回表。
例如:
SELECT amount
FROM orders
WHERE user_id = 1001;
如果只有索引 idx_user_id(user_id),二级索引里没有 amount 字段,那么查询过程大致是:
- 在
idx_user_id中找到user_id = 1001的记录; - 拿到对应主键
id; - 根据
id回到聚簇索引查询amount。
3.4 覆盖索引
如果查询需要的字段都能从二级索引中获取,就不需要回表,这就是覆盖索引。
例如:
CREATE INDEX idx_user_status ON orders(user_id, status);
SELECT user_id, status
FROM orders
WHERE user_id = 1001;
这个查询只需要 user_id 和 status,而它们都在联合索引中,因此可以直接从二级索引返回结果。
3.5 页分裂与自增主键
InnoDB 以页为单位管理索引数据。插入新记录时,如果目标页空间不足,可能会发生页分裂。
自增主键通常更适合 InnoDB 的原因:
- 新记录大多插入到聚簇索引末尾;
- 写入路径更顺序;
- 页分裂相对更少;
- 页利用率更稳定。
随机主键,例如完全随机 UUID,可能导致:
- 插入位置分散;
- 更频繁的页分裂;
- 页利用率下降;
- 缓存命中率下降;
- 写放大增加。
这并不意味着 UUID 一定不能用,而是需要结合业务场景、分库分表、全局唯一性和写入性能综合选择。
4. B+树与 SQL 查询
4.1 等值查询
CREATE INDEX idx_user_id ON orders(user_id);
SELECT *
FROM orders
WHERE user_id = 1001;
B+ 树可以从根节点逐层定位到包含 user_id = 1001 的叶子节点,快速找到对应记录。
4.2 范围查询
CREATE INDEX idx_create_time ON orders(create_time);
SELECT *
FROM orders
WHERE create_time >= '2024-01-01 00:00:00'
AND create_time < '2024-02-01 00:00:00';
B+ 树先定位范围起点,再沿叶子节点链表顺序扫描到范围终点,因此非常适合范围查询。
4.3 联合索引与最左前缀原则
CREATE INDEX idx_user_status_time
ON orders(user_id, status, create_time);
这个联合索引可以较好支持:
WHERE user_id = 1001;
WHERE user_id = 1001
AND status = 'PAID';
WHERE user_id = 1001
AND status = 'PAID'
AND create_time >= '2024-01-01'
AND create_time < '2024-02-01';
但通常不能直接高效支持:
WHERE status = 'PAID';
因为联合索引 (user_id, status, create_time) 是按照 user_id、status、create_time 的顺序组织的,这就是最左前缀原则。
4.4 ORDER BY 与 GROUP BY
如果排序字段和索引顺序一致,数据库可以利用 B+ 树的有序性减少额外排序。
例如:
CREATE INDEX idx_user_time
ON orders(user_id, create_time);
SELECT *
FROM orders
WHERE user_id = 1001
ORDER BY create_time DESC;
这种场景有机会利用索引顺序完成排序,减少 filesort 成本。实际是否使用索引,还要结合选择度、返回行数和优化器成本判断。
5. B+树与其他数据结构对比
5.1 B 树
B 树也可以用于索引,但由于内部节点也可能保存数据,节点能容纳的索引键更少,树高可能更高;范围查询也不如 B+ 树的叶子链表顺序扫描友好。
5.2 红黑树
红黑树适合内存中的有序结构,但每个节点只有两个子节点。用于磁盘索引时,树高明显高于 B+ 树,访问路径更长,磁盘 I/O 成本更高。
5.3 哈希表
哈希表适合等值查询,平均时间复杂度接近 O(1),但不适合范围查询和排序。
例如:
WHERE id = 1001
哈希索引可能很快;但:
WHERE id BETWEEN 1000 AND 2000
哈希结构就不如 B+ 树适合。
5.4 LSM Tree
LSM Tree 更适合写入密集场景,常见于一些 NoSQL、分布式数据库和日志结构化存储系统。它通过顺序写和后台合并提升写入性能,但读放大、空间放大和 Compaction 成本需要额外权衡。
6. 常见问题
6.1 为什么数据库索引常用 B+树?
因为 B+ 树同时满足:
- 树高低,减少磁盘 I/O;
- 叶子节点有序,适合范围查询;
- 内部节点只存索引,扇出高;
- 适合页缓存;
- 支持等值、范围、排序等多类查询。
6.2 为什么二级索引会回表?
因为 InnoDB 二级索引叶子节点通常保存的是索引列和主键值,而不是完整行数据。如果查询字段不在二级索引中,就需要再根据主键去聚簇索引查询完整行。
6.3 覆盖索引为什么快?
覆盖索引可以直接从二级索引中返回查询所需字段,避免回表,减少一次聚簇索引查找。
6.4 UUID 主键一定不好吗?
不一定。UUID 的优势是全局唯一、分布式友好,但完全随机 UUID 可能导致聚簇索引随机插入和页分裂。实际设计时需要在全局唯一性、写入性能、存储空间和业务需求之间权衡。
7. 总结
B+ 树之所以适合数据库索引,并不是因为它单点查询一定比哈希表快,而是因为它在磁盘 I/O、范围查询、有序扫描、页缓存和大规模数据管理之间取得了很好的平衡。
在 MySQL InnoDB 中,理解 B+ 树还需要进一步理解:
- 聚簇索引;
- 二级索引;
- 回表;
- 覆盖索引;
- 联合索引;
- 页分裂;
- 自增主键。
掌握这些概念后,再去分析 SQL 执行计划、索引设计和查询优化,会更加清晰。