RocketMQ 架构设计与应用最佳实践:高可用消息队列核心解析
RocketMQ 架构设计与应用最佳实践:高可用消息队列核心解析
前言
RocketMQ 是一款开源的分布式消息队列系统,具备高吞吐、低延迟、高可靠等特点,常见于金融、电商、物流、订单、支付、异步解耦和削峰填谷等高并发场景。
本文主要基于 RocketMQ 4.x 经典架构 进行整理,重点关注 NameServer、Broker、Producer、Consumer、Remoting 与 Store 等核心模块,并结合消息轨迹、存储模型、生产端 FastFail、事务消息、顺序消息和高可用部署,总结 RocketMQ 在高并发场景下的架构设计与应用最佳实践。
说明:RocketMQ 5.x 在领域模型、Proxy、SimpleConsumer、云原生能力等方面有新的组件和表达方式。阅读本文时,可以将其作为 RocketMQ 4.x 经典架构的学习笔记,并结合官方 5.x 文档对照理解。
1. RocketMQ 整体架构
1.1 网络拓扑架构
- 网络架构拓扑:2M / M-S / NM-NS /主从切换/ 云服务(计算存储分离,如 pulsar)
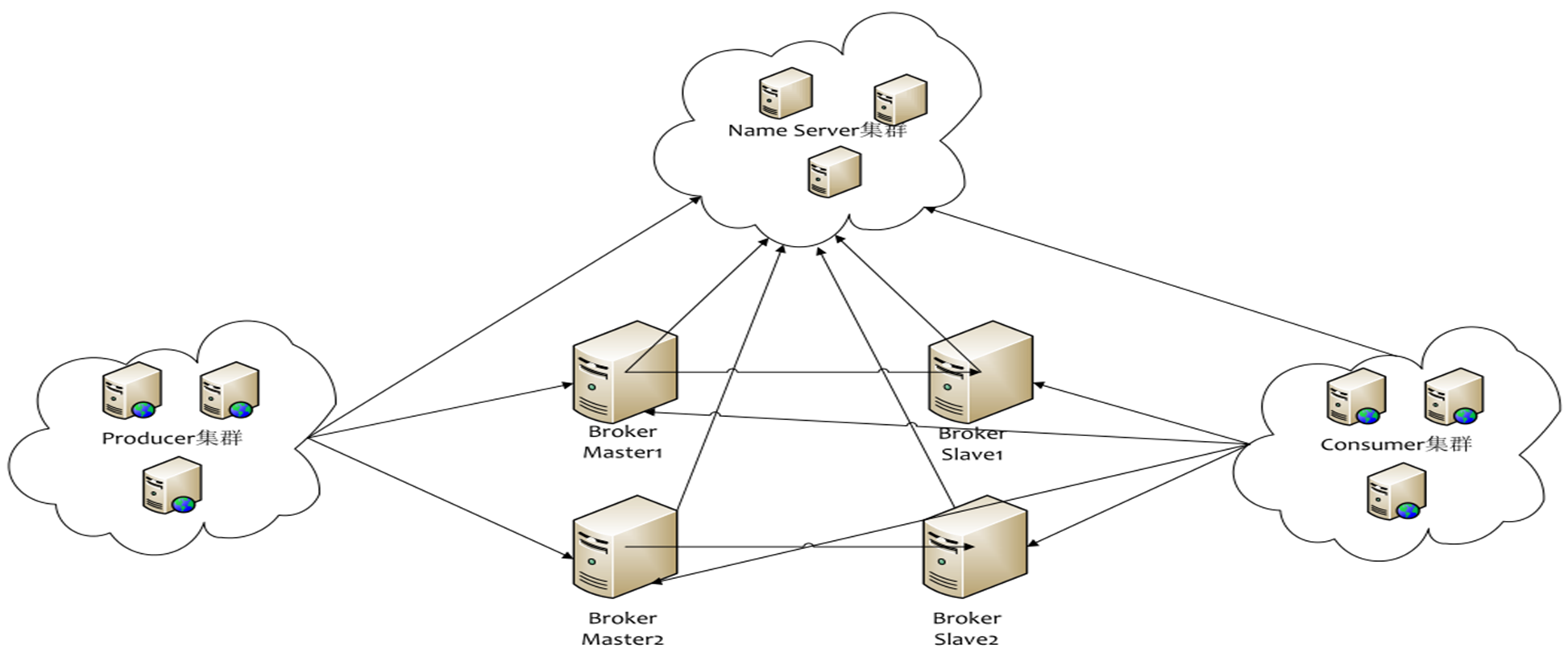
1.2 核心模块组成
- Common 公共模块
- NameServer 模块(注册中心)
- Remoting 通信模块(基于 Netty)
- Client 模块(生产消费者)
- Broker 模块(MQServer 服务模块)
- Store 模块(存储层)
1.3 核心设计优势
-
核心设计:
- Broker
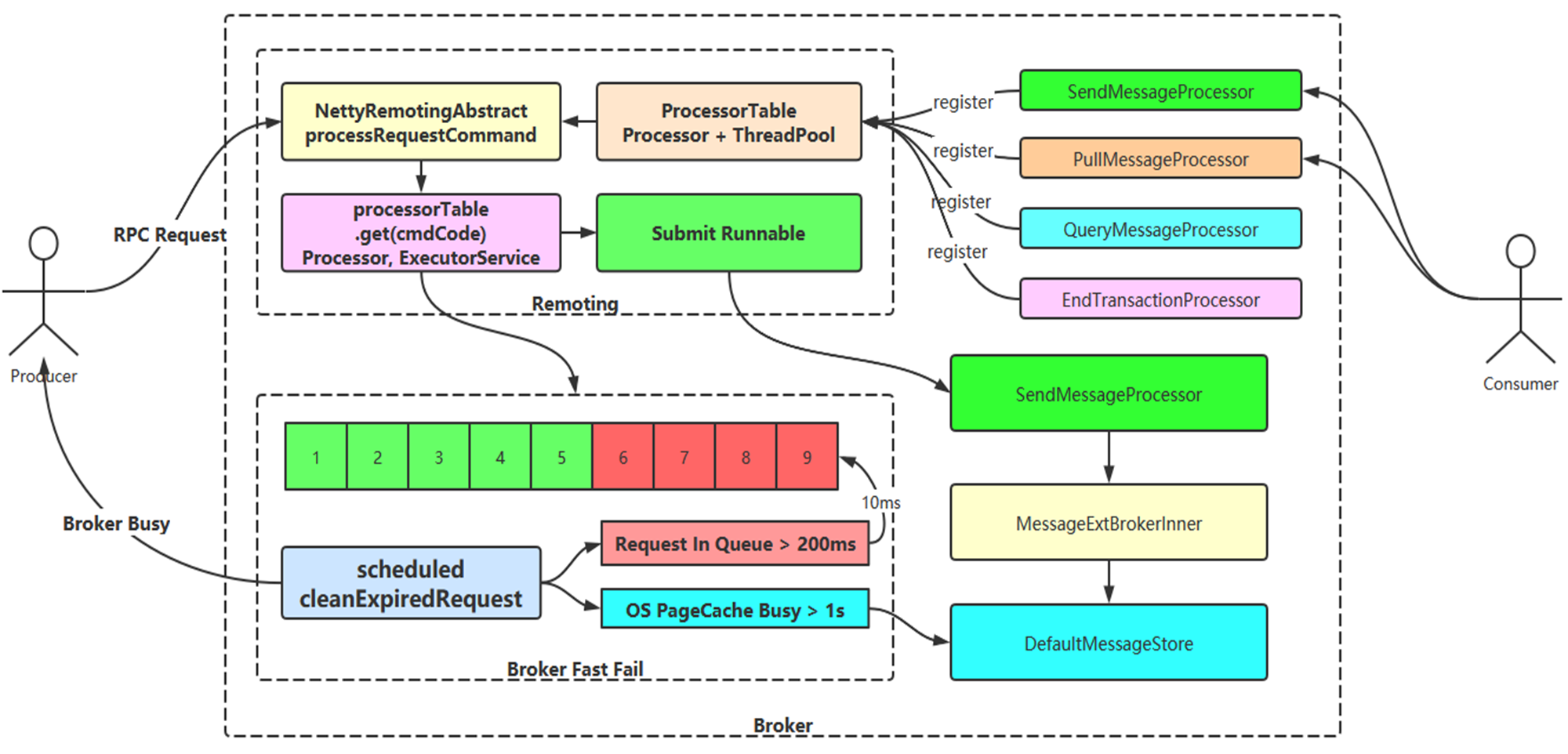
- 实现 FastFail 机制,在写盘出现瓶颈的时候,根据内存序列化的延迟时间会自动触发自我保护的机制;
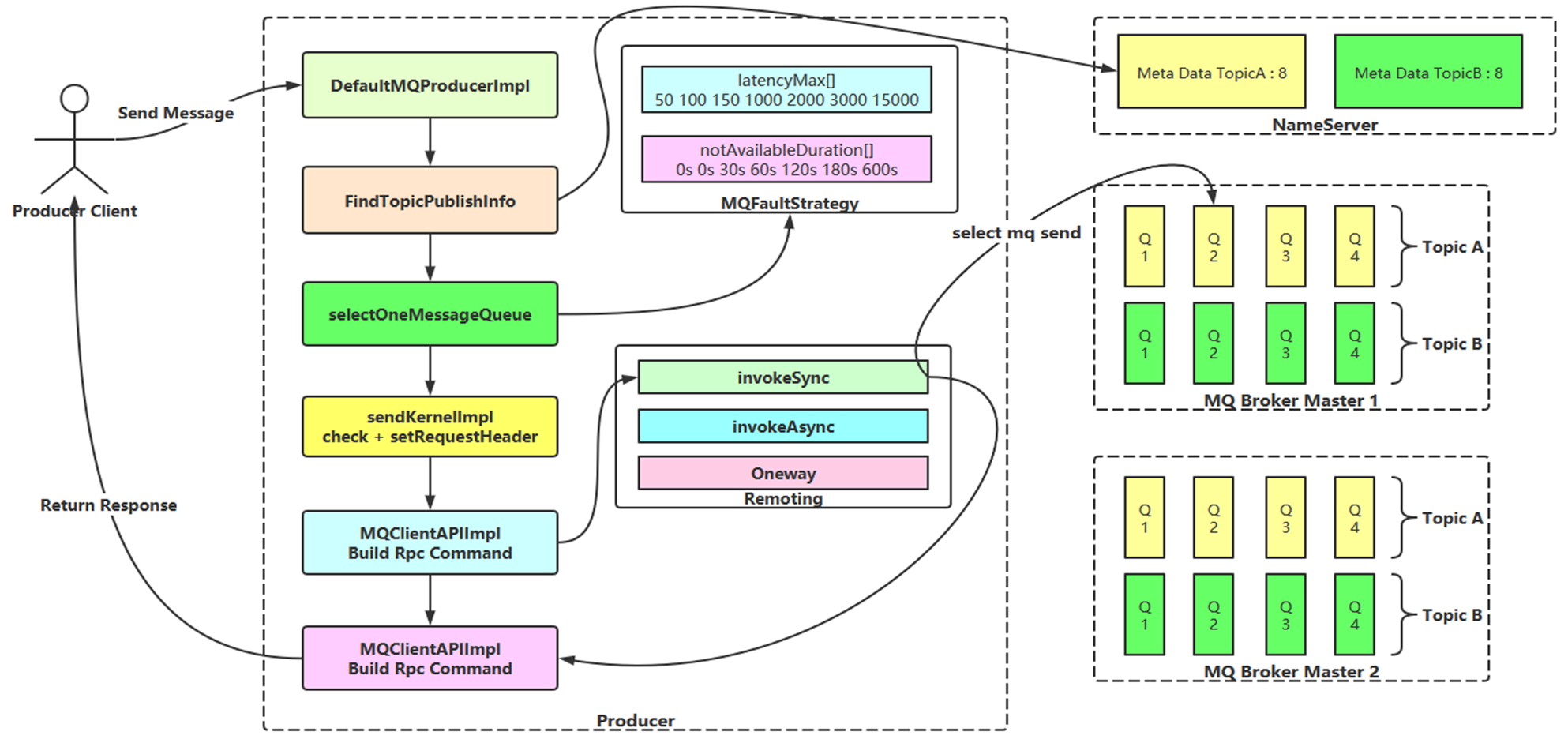
- Client
- 生产端:Latency 消息投递路由策略,保证延迟更低的 Broker 优先投递,延迟高的 Broker 自动剔除与恢复,提升了生产端消息发送的性能;
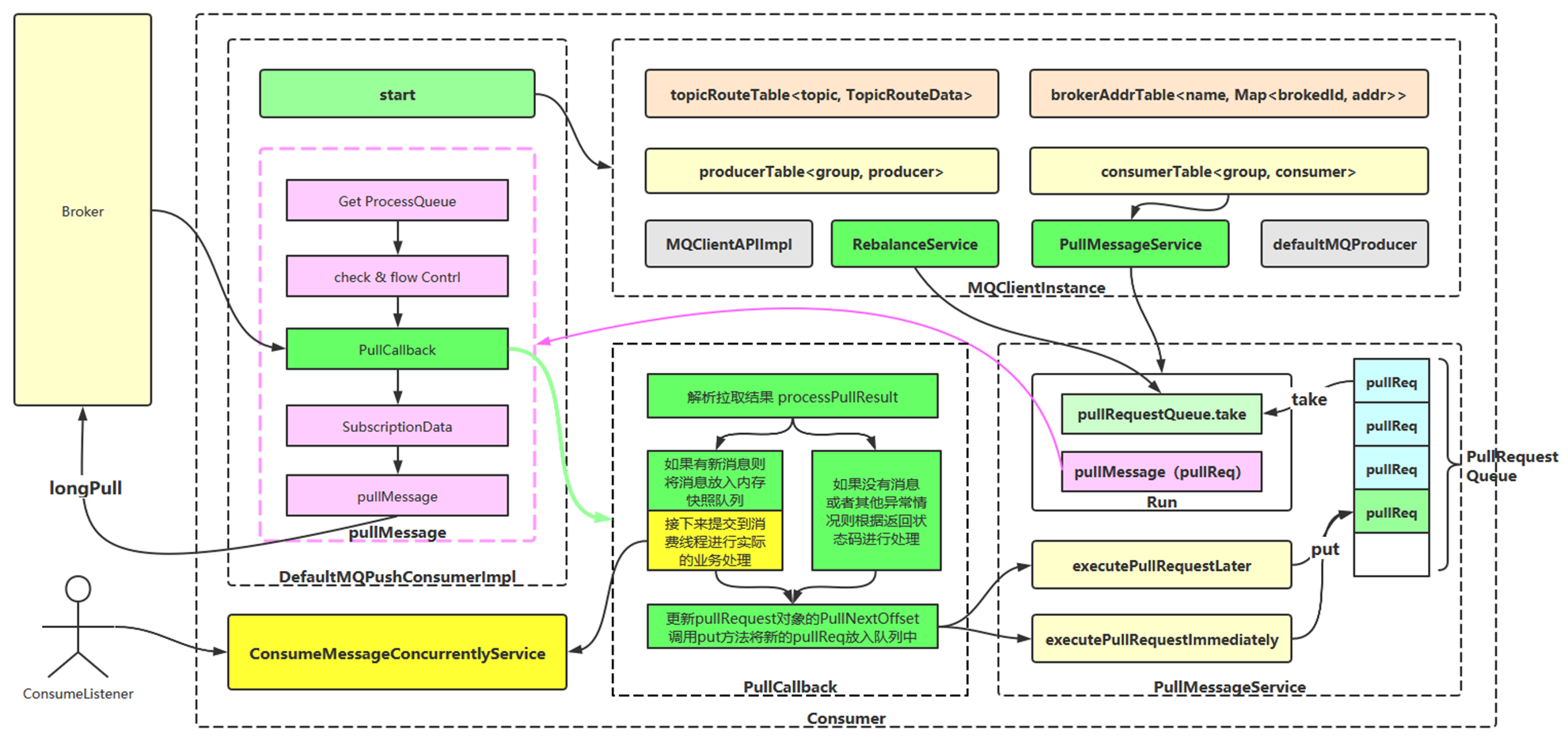
- 消费端:采用拉取模式,长轮询模式(longpolling)降低 Broker 主动推送消息的压力,在 Consumer 端做拉取;
- Remoting
- 基于 Netty 实现网络通信,使用自定义协议进行请求与响应编解码,具备轻量、高性能和长连接通信能力;
- Store
- 存储结构:CommitLog + ConsumeQueue + IndexFile
- 内存序列化:顺序写机制,充分借力于 OS PageCache 与 ZeroCopy 机制,通过 MappedByteBuffer(内存映射)对文件进行读写操作;优秀的隔离策略将内存操作与物理操作线程异步化等等
- 读写分离:DirectBuffer 堆外内存写、MappedByteBuffer 内存映射读
- 物理文件内存预加载、预热机制等优秀的思想
- JNA 锁内存:提升文件读写效率、防止资源不足时发生内存 SWAP
- Broker
-
易用性好,容错性强,API 功能强大;
-
生产者
- 支持消息同步、异步、单向、事务消息,各种灵活性配置
- 支持消息批量发送、消息压缩、自定义属性透传设置等
-
消费者
- 支持集群、广播模式,消费端支持推拉、定时消费模式
- 消费方式支持并发、顺序消息
- 支持消息过滤 Tag、支持标准 SQL 语法过滤
- 消费端支持多种 MessageQueue 分配策略,可根据业务场景选择平均分配、一致性哈希等策略
- 容错性支持消息重试策略、精准消息回溯(按时间戳)、支持流控、支持并发跨度设置等等
2. 消息发送与消费链路
RocketMQ 的消息链路可以拆成生产者发送、Broker 接收、Store 持久化、消费者拉取和消费者消费几个阶段。理解这条链路,有助于定位消息发送失败、消费堆积、存储瓶颈和 Broker 流控等问题。
2.1 消息轨迹跟踪
- 全链路消息轨迹流程
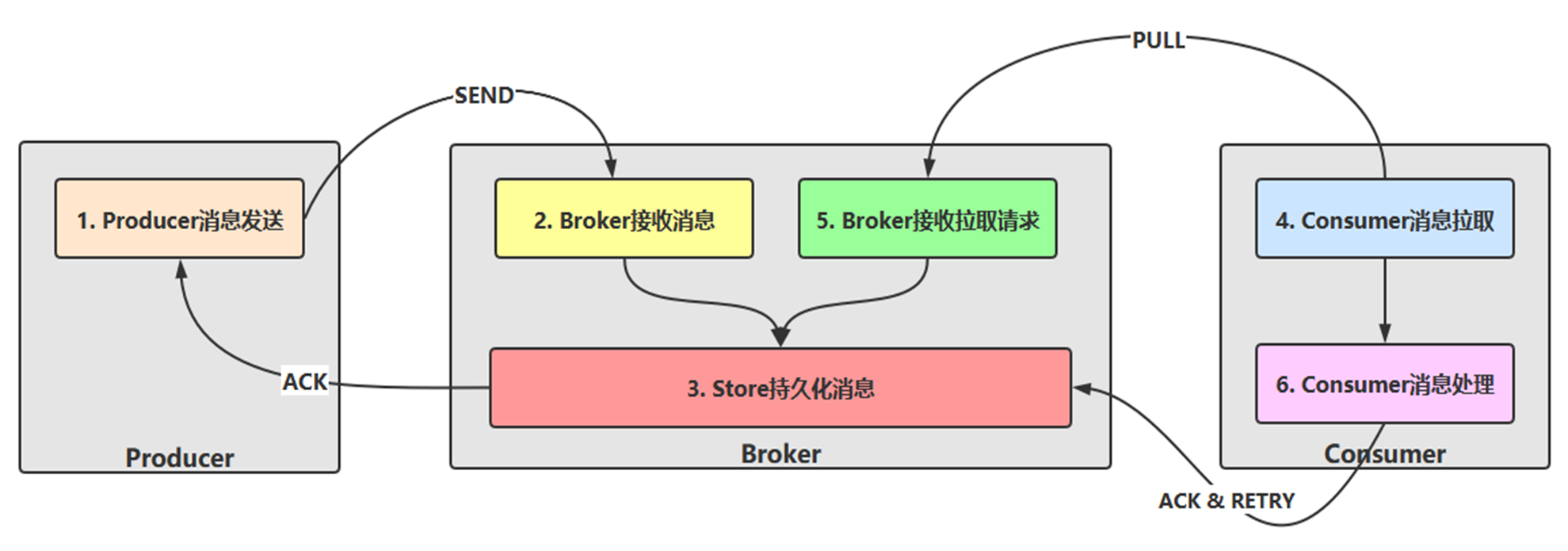
- Client 端(生产者)发送消息流程图
- Broker 层接收消息流程图
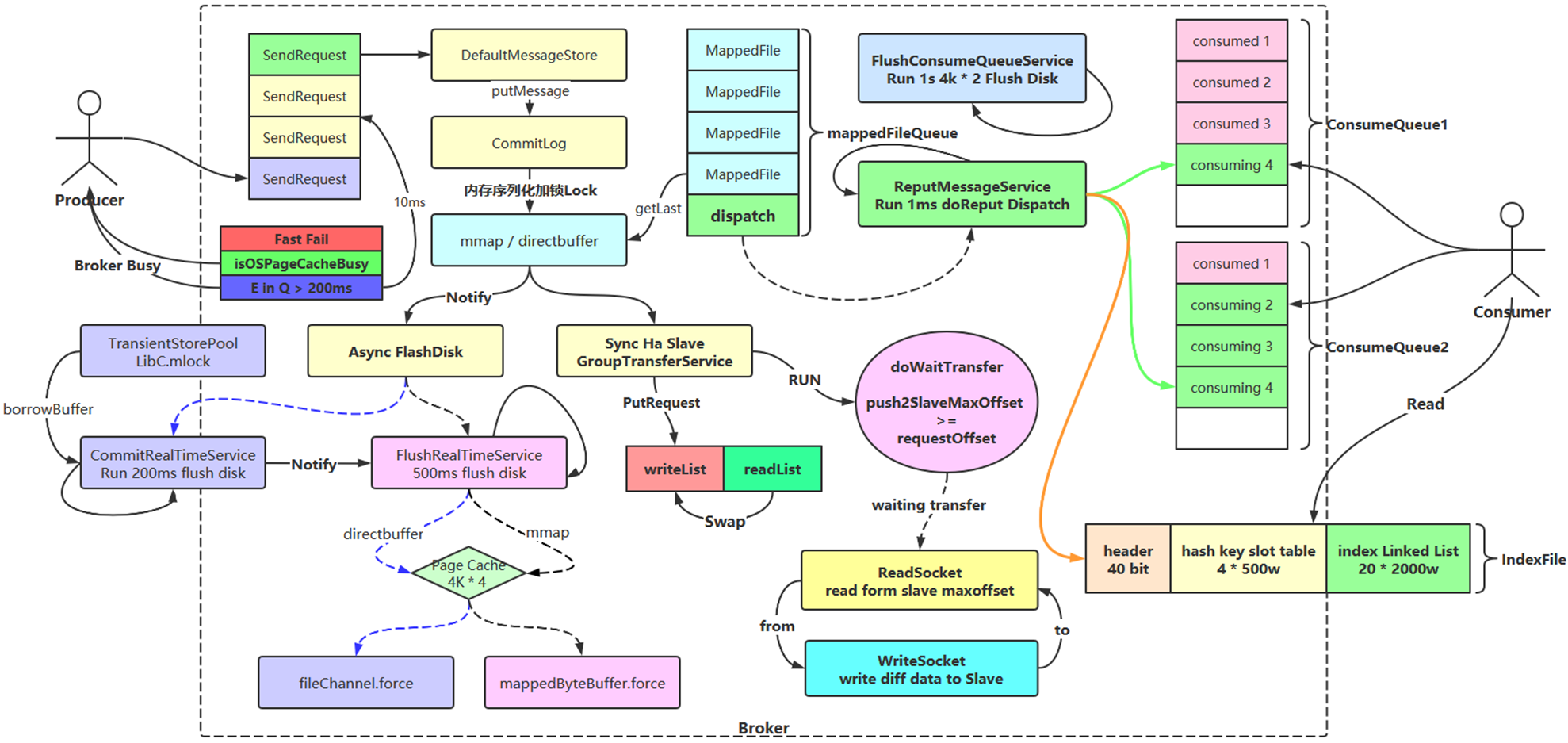
- Store 层持久化消息流程图
- Client 端(消费端)消息拉取流程图
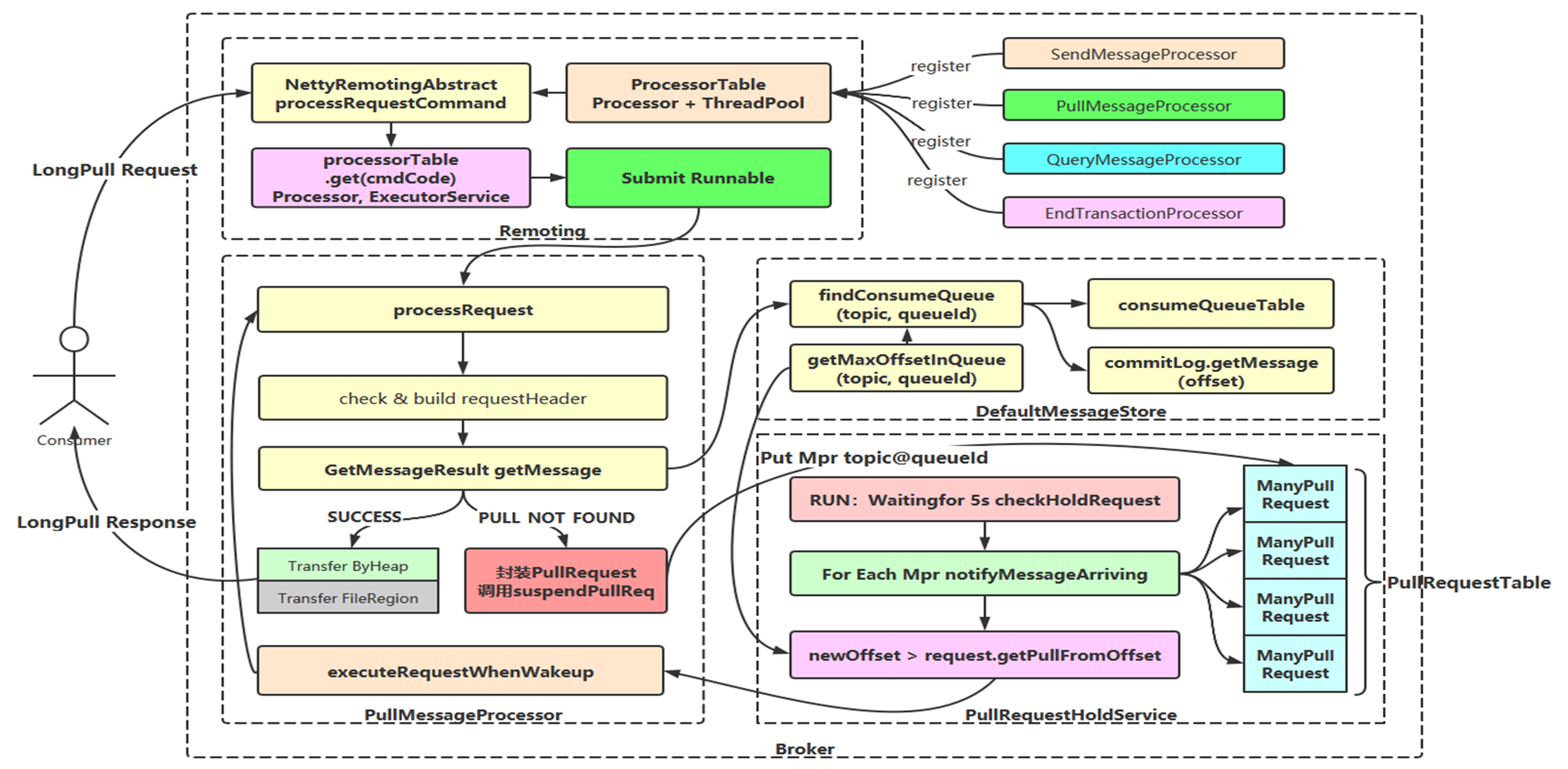
- Broker 端接收拉取请求流程图
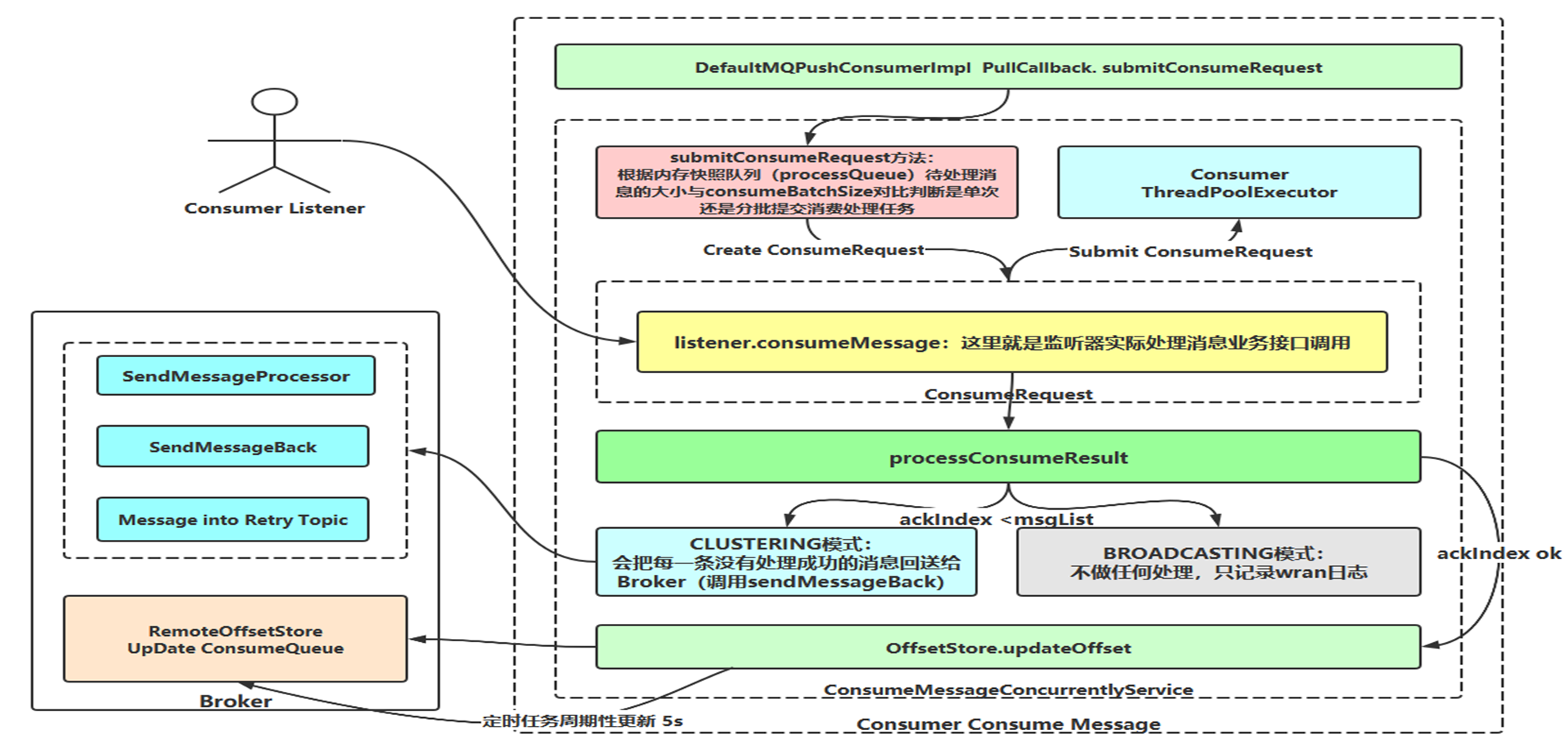
- Client 端(消费端)消息消费流程图
3. 存储设计
RocketMQ 存储层的核心是 CommitLog + ConsumeQueue + IndexFile。其中 CommitLog 负责顺序写入消息,ConsumeQueue 负责构建面向消费的逻辑队列,IndexFile 用于按 Key 或时间范围查询消息。
3.1 存储层核心设计
- 业务层存储交互领域设计
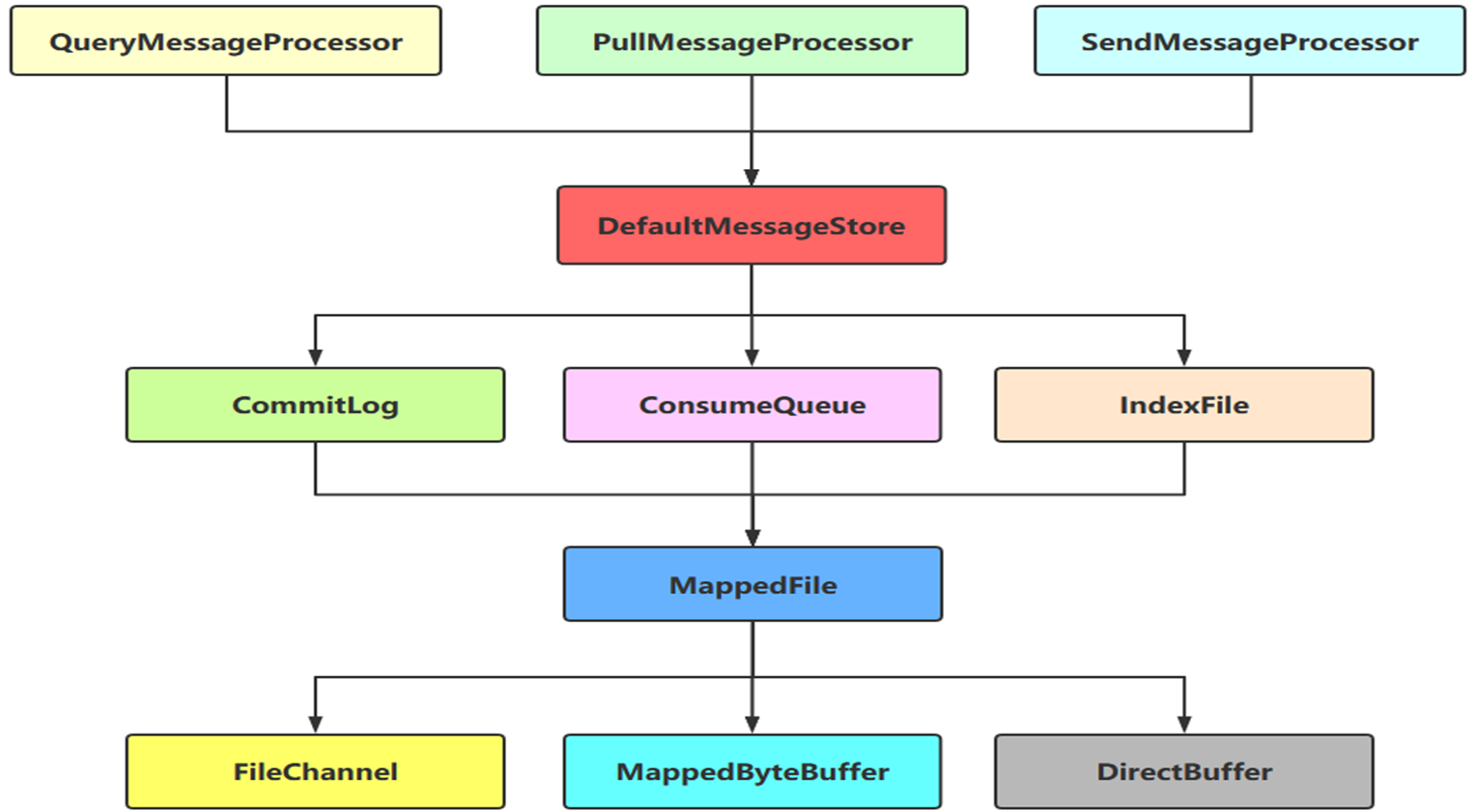
- DefaultMessageStore 核心功能实现
- FlushConsumeQueueService: 消息队列文件 ConsumerQueue 刷盘线程
- CleanCommitLogService:定时清理 CommitLog 文件;
- CleanConsumeQueueService :定时清理 ConsumeQueue 文件;
- IndexService:消息查询索引服务,用于查询消息;
- AllocateMappedFileService:MappedFile 分配服务,用于创建或删除 MappedFile;
- ReputMessageService:异步构建 ConsumeQueue(逻辑消费队列)和 IndexFile(索引文件)数据;
- HAService:用于主从数据同步;
- ScheduleMessageService:用于延迟消息的处理服务;
- StoreCheckpoint:文件检查点服务,用于故障恢复;
- StoreStatsService:存储的指标统计信息服务;
- BrokerStatsManager:Broker 统计信息服务;
- 底层存储核心类结构
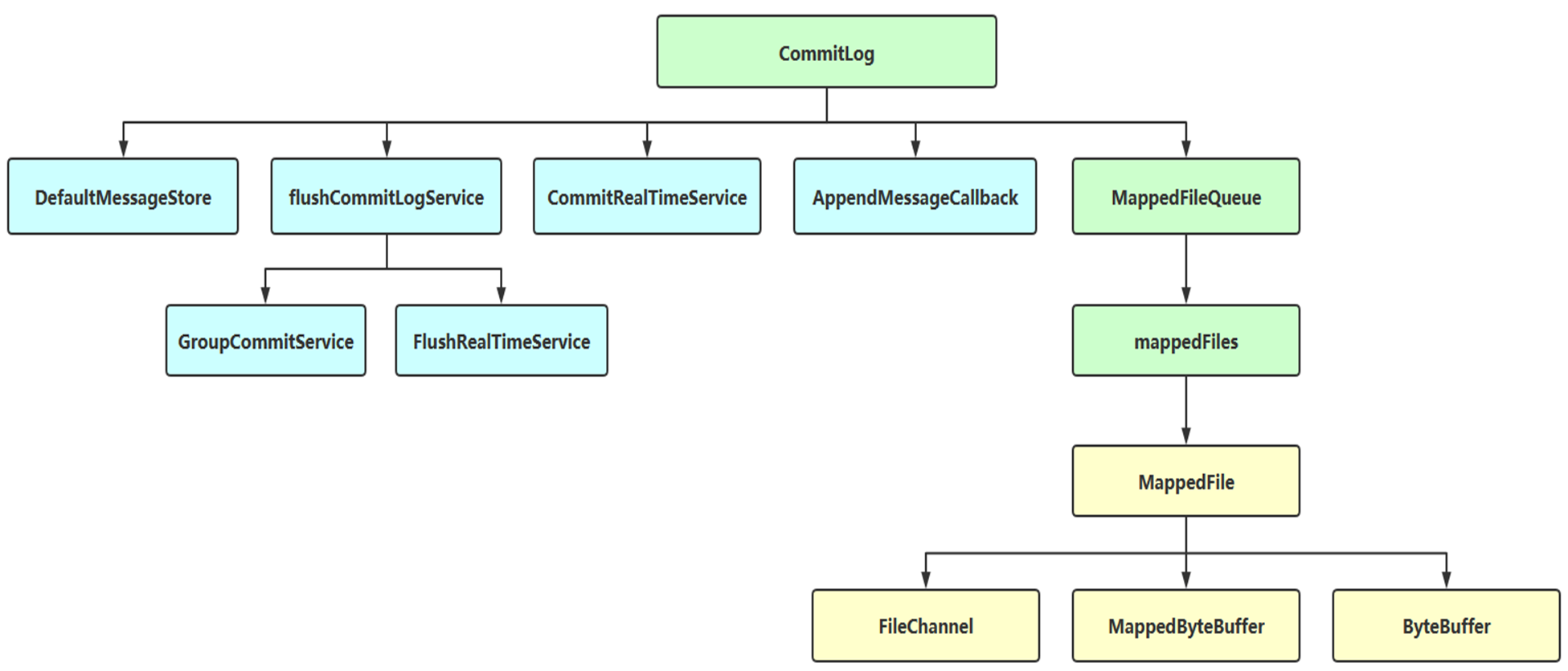
- 核心存储文件设计
- commitLog 文件结构设计
- 单个文件大小默认为 1G;文件名长度为 20 位,左边补零,剩余为起始偏移量,比如:00000000000000000000 代表了第一个文件,起始偏移量为 0,文件大小为 1G=1073741824
- 若第一个文件写满了,则会生成第二个文件,文件为 00000000001073741824,起始偏移量为 1073741824,以此类推。消息是顺序写入日志文件,当文件满以后,写入下一个文件
- ConsumeQueue 文件结构设计
- ConsumeQueue 文件夹的组织方式如下 topic/queue/file 三层组织结构;具体存储路径为:{usr.home}/store/consumequeue/{topic}/{queueId}/{fileName}
- ConsumeQueue 文件与 CommitLog 一样也是采取定长设计,每一个条目共 20 个字节,分别为 8 字节的 CommitLog 物理偏移量、4 字节的消息长度、8 字节 tag hashcode,单个文件由 30W 个条目组成,可以像数组一样随机访问每一个条目,每个 ConsumeQueue 文件大小约 5.72M
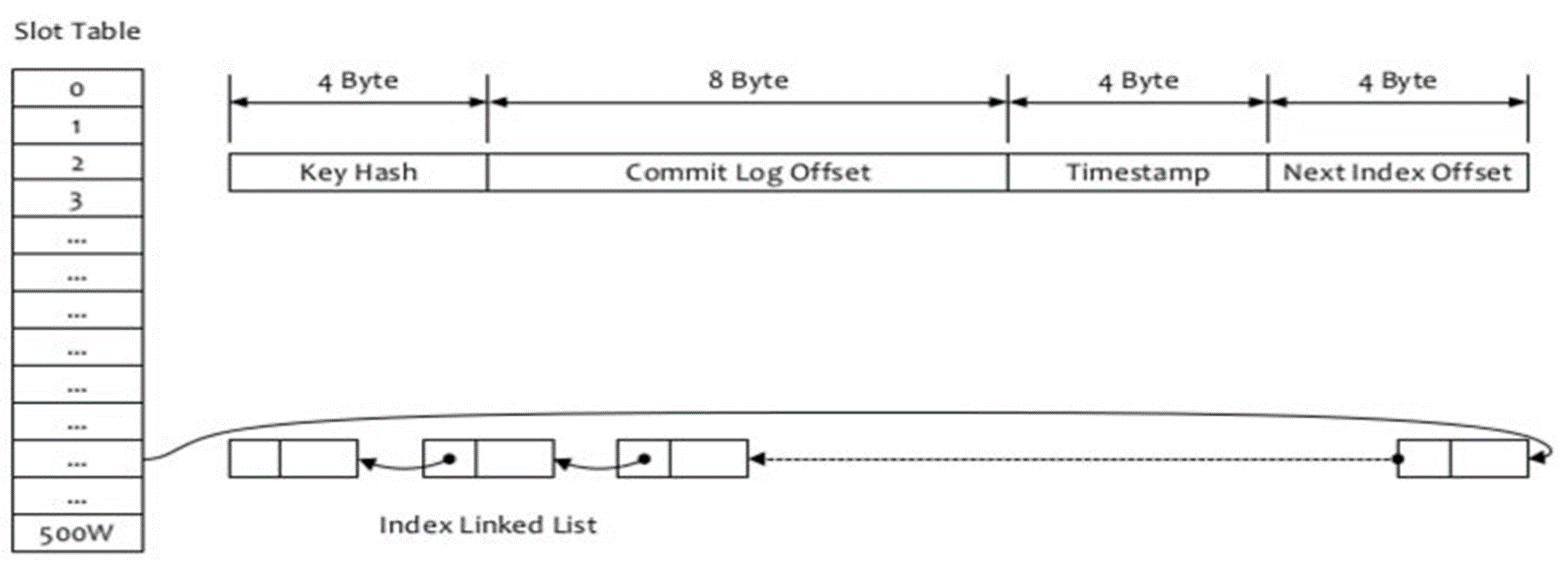
- Index 文件结构设计
-
IndexFile(索引文件)提供了一种可以通过 key 或时间区间来查询消息的方法。Index 文件的存储位置是:{usr.home}\store\index{fileName},文件名 fileName 是以创建时的时间戳命名的
-
固定的单个 IndexFile 文件大小约为 400M,一个 IndexFile 可以保存 2000W 个索引,IndexFile 的底层存储设计为在文件系统中实现 HashMap 结构,故 RocketMQ 的索引文件其底层实现为 Hash 索引
-
- commitLog 文件结构设计
4. 高可用设计
4.1 NameServer 高可用
NameServer 主要负责路由注册与发现,整体设计相对轻量,节点之间通常不进行复杂的数据同步。生产者和消费者可以配置多个 NameServer 地址,从而在单个 NameServer 不可用时继续获取路由信息。
实践建议:
- NameServer 至少部署 2 个以上节点。
- Producer、Consumer、Broker 都配置多个 NameServer 地址。
- NameServer 节点尽量分散在不同机器或不同可用区。
4.2 Broker 主从与复制机制
Broker 是消息写入、存储和消费的核心节点。为了提升可用性,RocketMQ 通常通过 Master/Slave 部署提升容灾能力。
常见关注点:
- 异步复制:写入性能更好,但极端故障下可能丢失少量未同步消息。
- 同步复制:可靠性更高,但写入延迟会增加。
- 异步刷盘:性能较高,适合大多数高吞吐场景。
- 同步刷盘:可靠性更高,适合对消息可靠性要求极高的场景。
4.3 DLedger 高可用模式
传统 Master/Slave 模式下,主节点故障后的切换通常需要额外运维或管控能力。DLedger 模式通过 Raft 协议实现多副本复制和主节点选举,可以提升 Broker 层的自动故障转移能力。
适用场景:
- 对 Broker 自动主从切换有要求。
- 希望降低人工切换成本。
- 对消息可靠性和集群可用性要求较高。
相关实践可参考文末的《RocketMQ DLedger 高可用集群搭建指南》。
4.4 生产端故障规避
Producer 侧可以通过以下机制提升可用性:
- 配置多个 NameServer。
- 合理设置发送超时与重试次数。
- 使用 Latency Fault Tolerance 规避延迟较高或异常的 Broker。
- 对重要消息做好本地事务、发送结果记录和补偿任务。
- 对大消息、批量消息和突发流量做好限流与降级。
4.5 消费端重试与容错
Consumer 侧需要重点关注:
- 消费失败后的重试策略。
- 死信队列 DLQ 的监控与处理。
- 消费堆积告警。
- 幂等处理,避免重复消费造成业务异常。
- 顺序消息场景下避免单队列阻塞扩大影响。
5. 最佳实践
5.1 生产端最佳实践
- 关于生产者应用的业务场景
- 一般性业务使用同步消息发送,注意两点即可
- 在代码的最后发送消息
- 完善且细粒度、准确的进行 try catch finally
- 对于高并发、对性能要求高的场景下,采用异步消息,注意点
- 在回调函数进行标记处理,但要注意 Broker ACK 响应请求抖动、断路问题,需要定时任务补偿
- 对于顺序消息,一般而言非必要场景不需要使用
- 一般的使用场景就是通过其业务 id(或关键路由字段),比如做 hash 操作等,可以路由到指定的队列;就如我们每个门店编号消费消息就可以采用其顺序消息;类似 kafka 的 partition,把相同业务属性的消息投递到一个队列里,保证局部有序且做消费区分
- 一般性业务使用同步消息发送,注意两点即可
- 对于重要不可丢失的消息
- 对本地事务与消息发送一致性要求较高的场景,可以选择事务消息;但事务消息会增加半消息存储、事务状态回查以及提交/回滚流程,不建议无差别滥用
- RocketMQ 事务消息并不会自动包裹业务数据库事务;业务侧仍需要自行控制本地事务的提交或回滚
- 要注意消息回调事务检查问题:TransactionalMessageServiceImpl#check 方法里的 needdiscard 方法,通过 TRANSACTION_CHECK_TIMES 属性设置了回查的次数(默认 15 次);这个属性也会带入到生产者回调检查函数里,也就是 15 次回查就会默认丢弃该消息(所以需要在回查函数里面把这个参数取到,判断其 TRANSACTION_CHECK_TIMES 次数,再次做 failover 记录人工处理
- 生产者到底是单条发送还是批量发送?
- 一般而言,我们倾向于消息的单条发送,rocketmq 默认消费 api 也是只处理一条消息,也说明了官方的倾向性
- 批量消费的场景诉求
- 首先可能是希望一批数据处理完成后一次性 commit;是要保障整体消息的原子性
- 如果业务诉求实际是可接受整体完整性的延迟完整性,那么我们可以把批量中失败的消息记录后重回队列后补偿处理
- 如果业务需要绝对的完整性,那么只能一次性提交,其中有失败就需要整体失败;这种情况可能会影响业务处理速度和性能,也会导致业务延迟和因为卡住
- 如果既要追求性能和数据强一致性,那我们架构设计一般会配合其他组件来完成;单靠 MQ 不能彻底解决该类问题
- 生产端 FastFail 机制流程
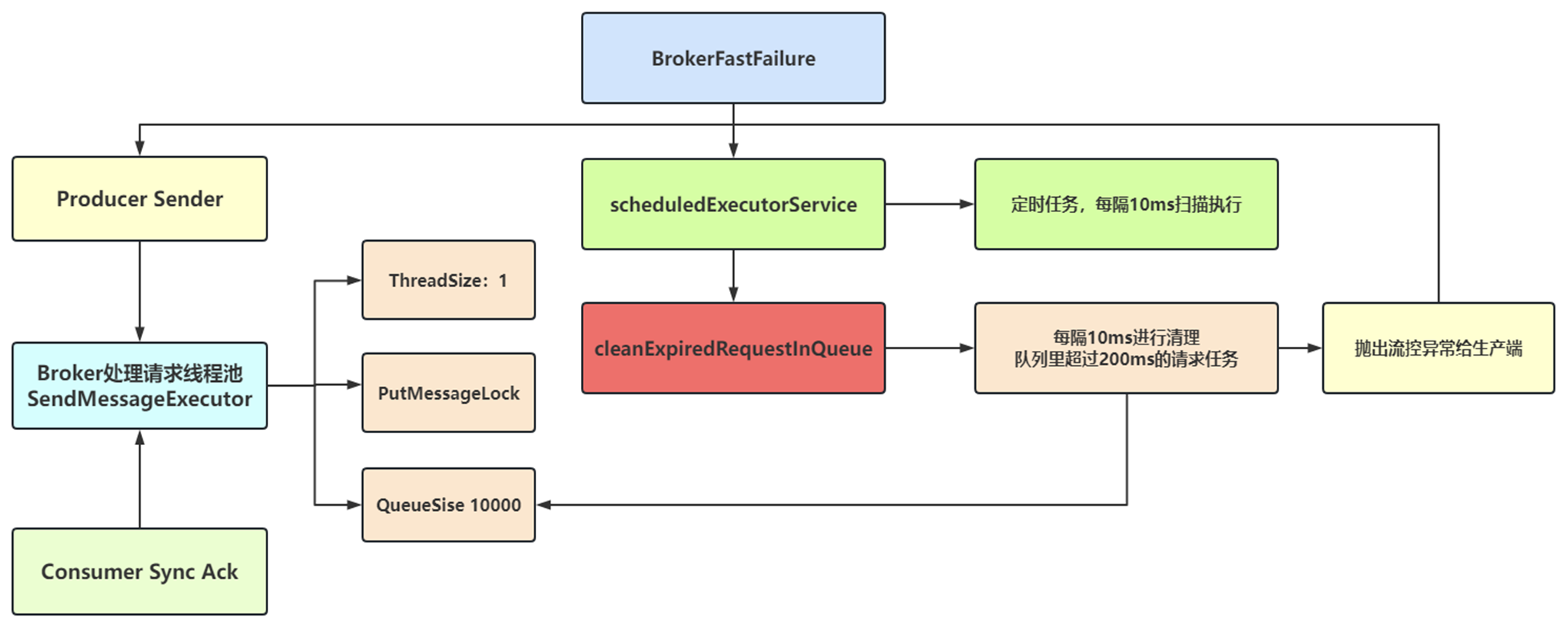
5.2 生产端 Case:发送失败与 FastFail
- 发送消息失败
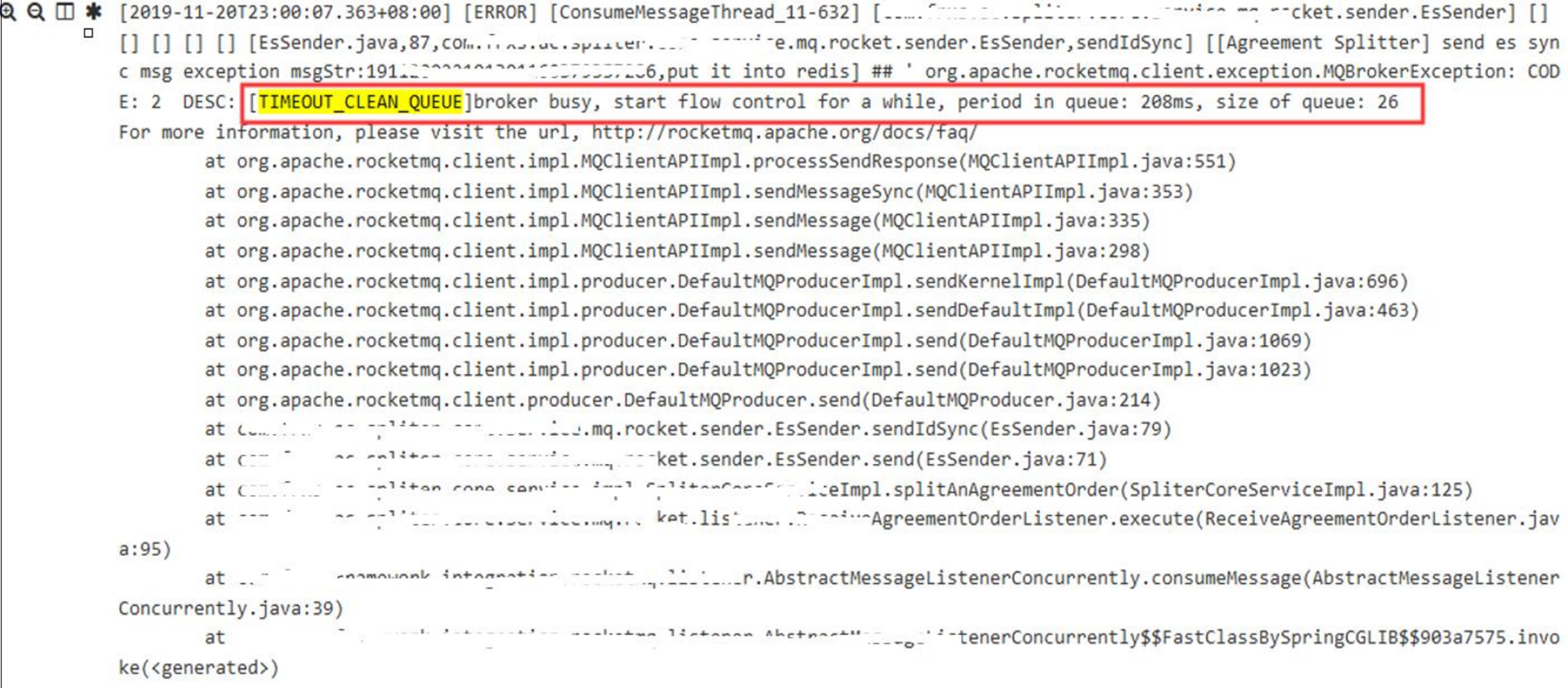
- 为什么发送失败?
- 首先在消息流量高峰期,一定是触发了两个情况
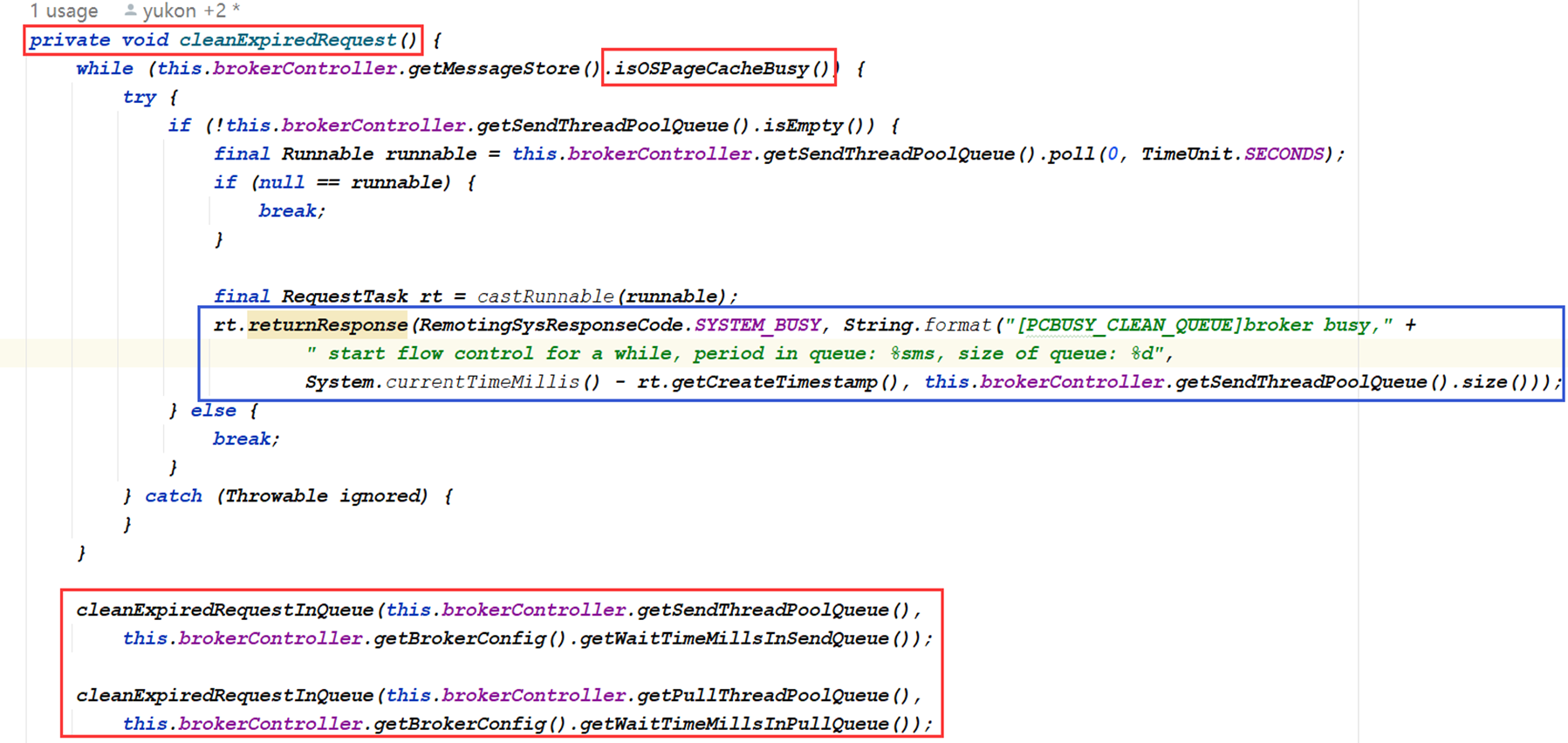
- 第一种:RocketMQ 首先判断的就是是否 OS Pagecache busy,他判断的依据就是内存序列化写盘大于 1 秒,我理解这种情况应该是什么原因?系统资源瓶颈 or 消息大报文
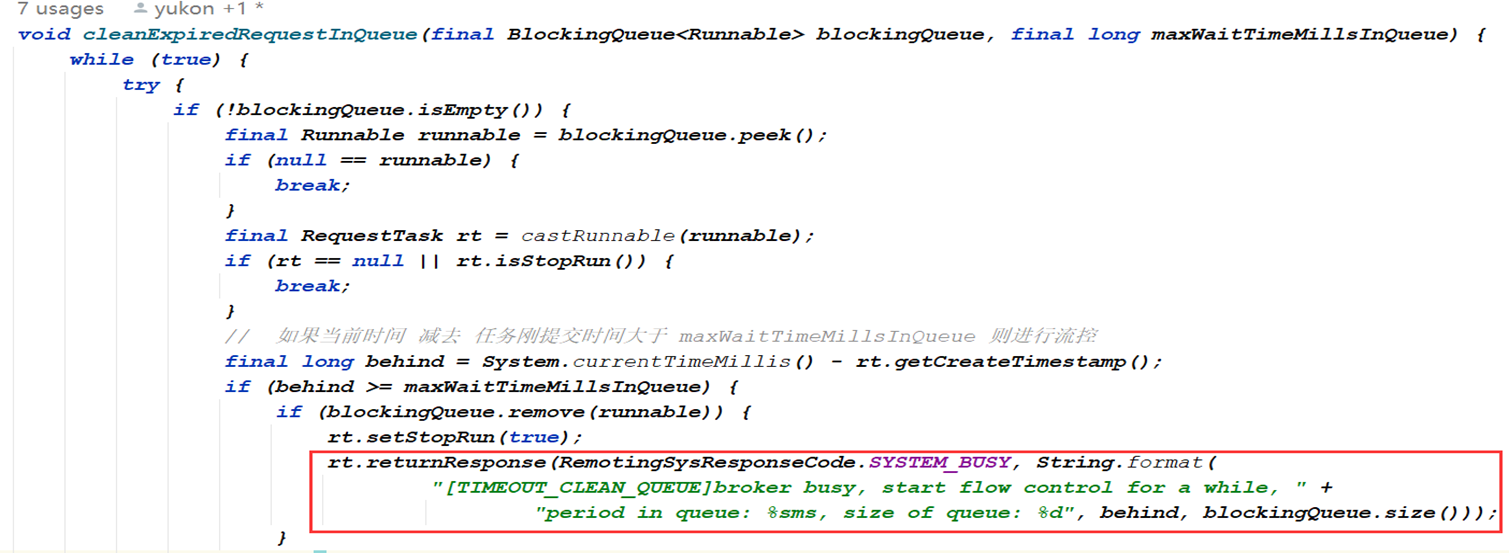
- 第二种:确实队列里消息量太大了,被流控了,通过 cleanExpiredRequestInQueue 字样就知道
- 首先在消息流量高峰期,一定是触发了两个情况
6. 常见问题与排查思路
6.1 发送失败如何排查?
优先检查:
- NameServer 是否可访问。
- Topic 路由是否存在。
- Broker 是否繁忙或触发流控。
- 是否出现
OS PageCache busy。 - 消息体是否过大。
- Producer 超时和重试配置是否合理。
6.2 消费堆积如何排查?
优先检查:
- 消费者实例数是否过少。
- 单条消息处理耗时是否过长。
- 是否存在消费失败反复重试。
- 顺序消息是否因单个队列阻塞导致整体延迟。
- 下游数据库、接口或缓存是否成为瓶颈。
6.3 如何选择同步刷盘与异步刷盘?
- 追求吞吐和低延迟:优先考虑异步刷盘。
- 追求更强可靠性:考虑同步刷盘,但需要接受写入延迟上升。
- 核心交易类消息:建议结合业务补偿、事务消息、同步复制等方案综合保障。
7. 总结
RocketMQ 通过 NameServer、Broker、Producer、Consumer、Remoting 和 Store 等模块协同,为分布式系统提供了高吞吐、低延迟和高可靠的消息传输能力。
理解 RocketMQ 的架构设计、消息链路、存储模型和高可用机制,可以帮助我们在实际业务中更好地处理削峰填谷、异步解耦、顺序消息、事务消息、消息堆积和故障恢复等问题。
在生产环境中,RocketMQ 的最佳实践并不只是“能发能收”,还需要关注:
- Broker 高可用部署;
- Producer 发送超时、重试和故障规避;
- Consumer 幂等、重试和死信处理;
- 存储刷盘、复制方式和磁盘水位;
- 监控告警与补偿机制。