APISIX kafka-logger 日志采集实践:写入 Kafka 并接入 Elasticsearch / Kibana
APISIX 作为 API 网关,天然位于流量入口位置,非常适合采集请求日志。通过 kafka-logger 插件,可以将网关访问日志写入 Kafka,再由 Logstash 消费并写入 Elasticsearch,最终在 Kibana 中检索和分析。
这篇文章整理一条常见链路:
Client -> APISIX -> kafka-logger -> Kafka -> Logstash -> Elasticsearch -> Kibana
如果还不了解 APISIX 插件和 Dashboard,可以先阅读:
为什么要把 APISIX 日志写入 Kafka
直接把日志写入 Elasticsearch 当然也可以,但引入 Kafka 有几个好处:
- 削峰填谷,避免日志高峰直接冲击 Elasticsearch。
- 解耦 APISIX 与日志存储系统。
- 支持多个消费者,例如实时告警、离线分析、审计归档。
- 方便后续扩展 Flink、ClickHouse、数据湖等链路。
但也要注意:日志链路越长,排查成本越高,需要配套监控 Kafka 堆积、Logstash 消费状态和 Elasticsearch 写入状态。
开启 kafka-logger 插件
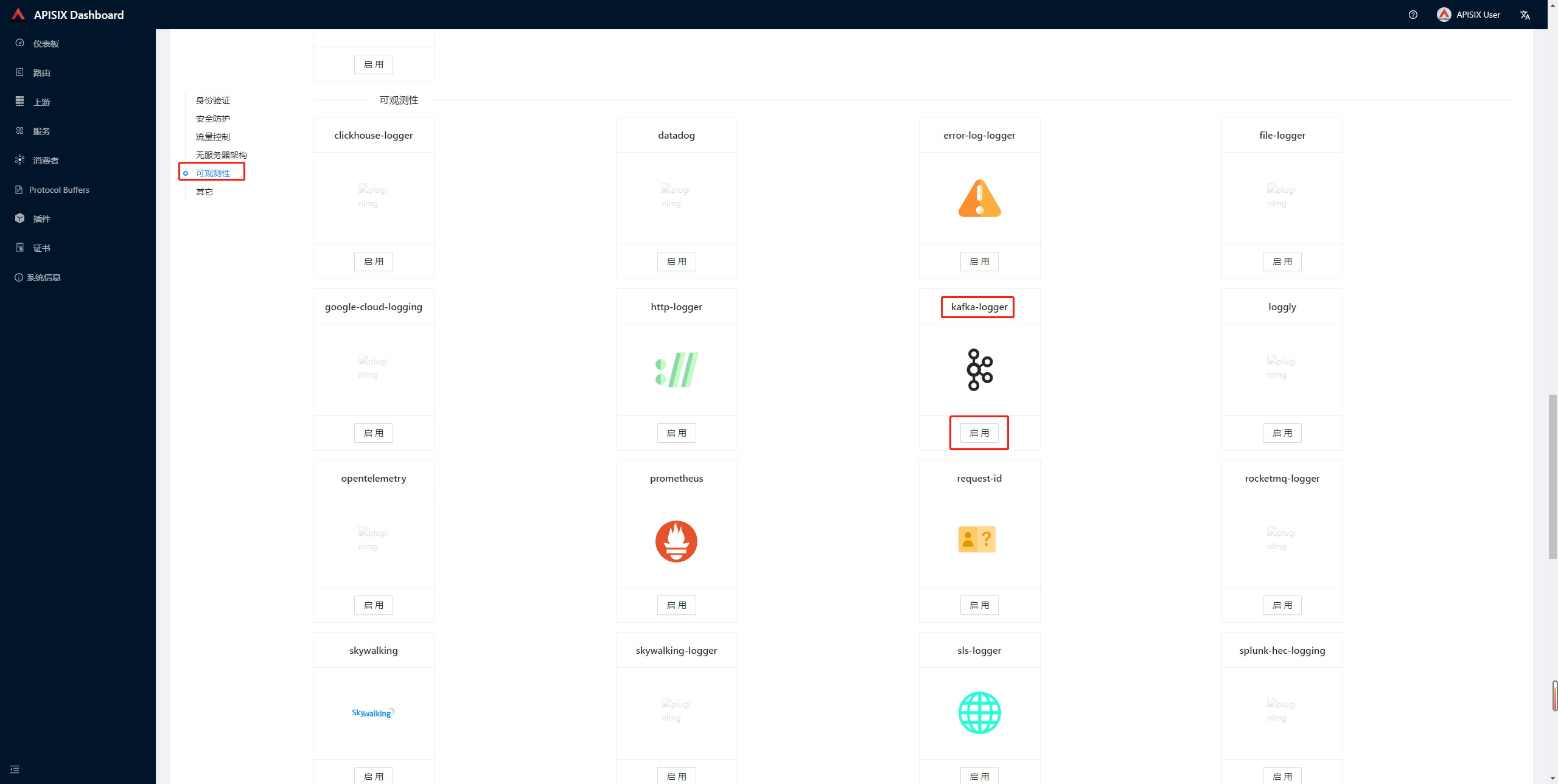
可以在 Dashboard 中进入插件列表,找到 kafka-logger 并启用。
示例配置:
{
"broker_list": {
"10.246.0.37": 9092,
"10.246.0.38": 9092,
"10.246.0.39": 9092
},
"kafka_topic": "apisix-logs",
"batch_max_size": 10,
"include_req_body": false,
"include_resp_body": false
}
关键参数:
| 参数 | 说明 |
|---|---|
broker_list |
Kafka Broker 地址列表 |
kafka_topic |
写入的 Kafka Topic |
batch_max_size |
批量发送日志的最大条数 |
include_req_body |
是否采集请求体 |
include_resp_body |
是否采集响应体 |
重要建议:生产环境不要默认开启 include_req_body 和 include_resp_body。请求体和响应体可能包含手机号、身份证、Token、密码、订单、支付等敏感信息,也会显著增加日志量。
Admin API 配置示例
可以将插件绑定到 Route:
curl -i "http://127.0.0.1:9180/apisix/admin/routes/log-demo" \
-H "X-API-KEY: your-admin-key" \
-X PUT \
-d '{
"uri": "/log-demo/*",
"plugins": {
"kafka-logger": {
"broker_list": {
"10.246.0.37": 9092,
"10.246.0.38": 9092,
"10.246.0.39": 9092
},
"kafka_topic": "apisix-logs",
"batch_max_size": 10,
"include_req_body": false,
"include_resp_body": false
}
},
"upstream": {
"type": "roundrobin",
"nodes": {
"127.0.0.1:1980": 1
}
}
}'
如果希望多个路由复用日志配置,可以考虑绑定到 Service 或使用全局规则,但要谨慎评估日志量。
Kafka Topic 规划
Topic 设计建议:
apisix-access-log
apisix-error-log
apisix-audit-log
也可以按环境区分:
dev-apisix-access-log
test-apisix-access-log
prod-apisix-access-log
生产建议:
- 为日志 Topic 设置合理分区数。
- 设置保留时间,避免 Kafka 磁盘被打满。
- 监控 consumer lag。
- 对重要日志链路配置副本数。
使用 Logstash 消费 Kafka
示例 logstash.conf:
input {
kafka {
bootstrap_servers => "10.246.0.37:9092,10.246.0.38:9092,10.246.0.39:9092"
topics => ["apisix-logs"]
client_id => "c_logstash_apisix"
group_id => "g_logstash_apisix"
auto_offset_reset => "latest"
codec => "json"
}
}
filter {
mutate {
add_field => { "log_source" => "apisix" }
}
}
output {
elasticsearch {
hosts => ["http://10.246.0.100:9200"]
index => "apisix-logs-%{+YYYY.MM.dd}"
}
}
启动 Logstash:
bin/logstash -f logstash.conf
如果日志格式不是标准 JSON,需要在 filter 阶段增加解析逻辑。
在 Kibana 中检索
在 Kibana 中可以按下面步骤查看:
- 创建 Index Pattern / Data View,例如:
apisix-logs-*。 - 选择时间字段。
- 在 Discover 中检索日志。
- 根据 URI、状态码、上游、客户端 IP、请求耗时等字段过滤。
常见检索方向:
- 统计 5xx 错误。
- 分析某个接口 P95 / P99 延迟。
- 查看某个客户端 IP 请求量。
- 排查某个时间段的异常请求。
- 分析上游服务错误分布。
日志字段建议
APISIX 日志字段会随版本和插件配置变化,建议至少关注:
- 请求时间。
- Client IP。
- Host。
- URI。
- Method。
- Status。
- Upstream 地址。
- 请求耗时。
- Upstream 耗时。
- Request ID / Trace ID。
- Consumer / Credential 信息。
如果系统已经接入链路追踪,建议在网关层透传 Trace ID,方便从 Kibana 跳转到链路追踪系统排查。
性能与安全注意事项
1. 请求体和响应体采集风险
默认不要采集 body。只有在明确需要排查问题时,才对特定路由临时开启,并设置脱敏策略。
风险包括:
- 敏感信息泄露。
- 日志量暴增。
- Kafka 和 Elasticsearch 成本上升。
- 大 body 影响网关性能。
2. 批量发送参数
kafka-logger 使用批处理机制。批量越大,吞吐越好,但日志延迟可能增加;批量越小,实时性更好,但发送压力更高。
建议通过压测和监控调整:
- batch size。
- flush interval。
- Kafka topic 分区。
- Logstash pipeline worker。
3. 失败处理
需要关注:
- Kafka 不可用时 APISIX 插件行为。
- 日志是否丢失。
- 是否有重试和缓冲。
- APISIX error.log 是否出现发送失败。
日志链路故障不应轻易影响核心业务请求,但也不能长期静默丢日志。
常见问题排查
1. Kafka 中没有日志
检查:
- 插件是否绑定到正确 Route / Service。
- 当前请求是否命中该路由。
- Kafka broker 地址是否可达。
- Topic 是否存在或允许自动创建。
- APISIX error.log 是否有发送失败。
2. Logstash 消费不到数据
检查:
topics是否正确。group_id是否重复导致消费位置不符合预期。auto_offset_reset设置。- Kafka consumer lag。
- Logstash pipeline 是否启动成功。
3. Elasticsearch 没有索引
检查:
- Logstash output 是否连接成功。
- Elasticsearch 用户权限。
- index 名称是否符合规范。
- Kibana Data View 是否匹配。
总结
APISIX + Kafka + Logstash + Elasticsearch / Kibana 是一条常见的网关日志链路。设计时要重点关注:
- 日志采集范围。
- 是否采集请求体 / 响应体。
- Kafka Topic 和分区规划。
- Logstash 消费能力。
- Elasticsearch 索引生命周期。
- 敏感信息脱敏。
- 监控和告警。
日志链路不是“能写进去”就结束了,更重要的是可检索、可排查、可控成本和不泄露敏感数据。