PCTA 学习笔记:TiDB 核心原理、TiKV 存储与 HTAP 架构解析
PCTA 学习笔记:TiDB 核心原理、TiKV 存储与 HTAP 架构解析
前言
TiDB 是 PingCAP 开源的分布式关系型数据库,兼容 MySQL 协议,面向水平扩展、金融级高可用、分布式事务和实时 HTAP 场景。
这篇文章基于 PCTA 学习笔记重新整理,重点回答几个问题:
- TiDB 为什么可以做到 SQL 层无状态扩展?
- 表数据如何从关系模型映射到分布式 KV?
- TiKV 如何通过 RocksDB、Region、Raft 和 MVCC 存储数据?
- PD 为什么既是元数据中心,也是调度中心和 TSO 服务?
- TiFlash 如何通过列存和 Raft Learner 支撑 HTAP?
- 一条 SQL 在 TiDB 中如何被解析、优化、下推和执行?
如果用一句话理解 TiDB:
TiDB Server 负责 SQL 计算,PD 负责元数据和调度,TiKV 负责行存事务数据,TiFlash 负责列存分析加速。
TiDB 整体架构
TiDB 的整体架构可以分为三层:
Client / MySQL Protocol
↓
TiDB Server:SQL 层,无状态,可水平扩展
↓
PD:元数据、TSO、Region 调度、集群管理
↓
TiKV:行存、分布式事务、Raft 多副本
TiFlash:列存、分析查询、HTAP 加速
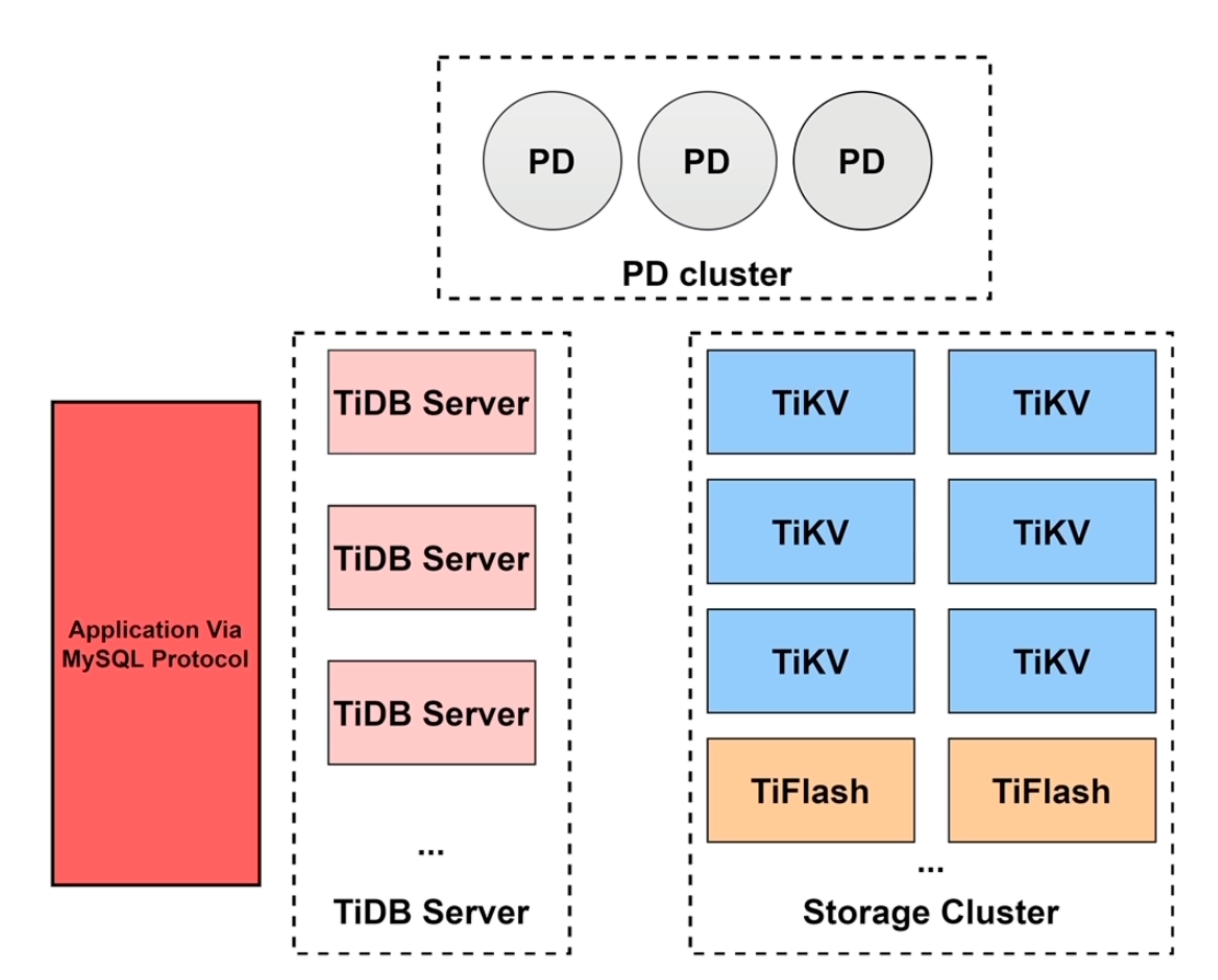
从职责上看:
| 组件 | 角色 | 是否有状态 | 核心职责 |
|---|---|---|---|
| TiDB Server | SQL 计算层 | 无状态 | 连接管理、SQL 解析、优化、执行、事务协调 |
| PD | 调度与元数据层 | 有状态 | TSO、Region 元数据、调度、高可用拓扑 |
| TiKV | 行存储层 | 有状态 | 分布式 KV、Raft 副本、MVCC、事务数据 |
| TiFlash | 列存储层 | 有状态 | OLAP 加速、列式存储、HTAP 隔离 |
TiDB Server 不保存用户数据,因此可以通过负载均衡器横向扩展;真正的数据存储在 TiKV / TiFlash 中,由 PD 负责感知和调度。
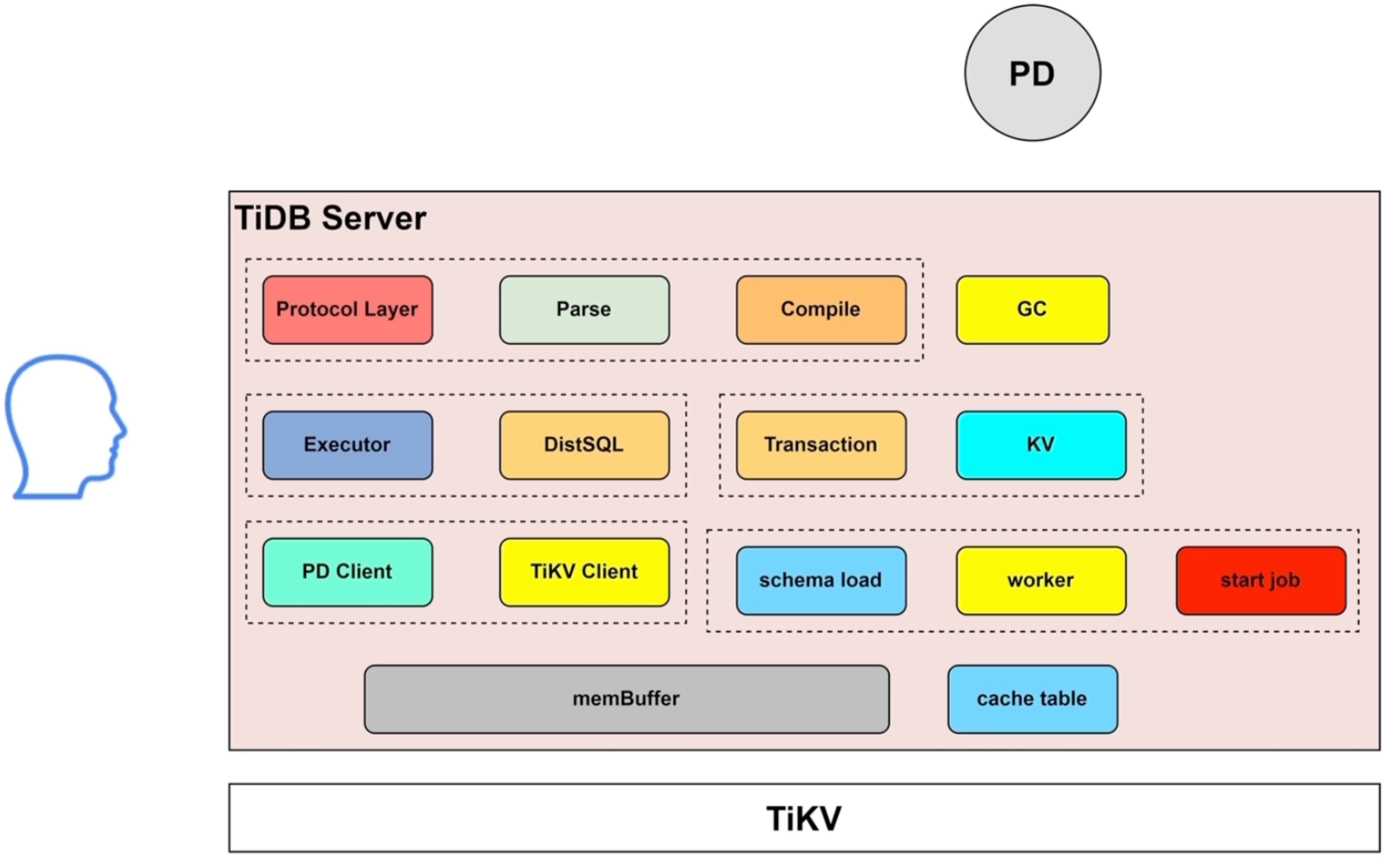
TiDB Server:无状态 SQL 层
TiDB Server 面向客户端暴露 MySQL 协议,负责将 SQL 请求转换为分布式 KV 访问。
主要功能包括:
- 处理客户端连接;
- SQL Parse / Compile / Optimize;
- 生成逻辑计划和物理计划;
- 将关系模型转换为 Key-Value 访问;
- 执行 DistSQL,把部分算子下推到 TiKV / TiFlash;
- 协调分布式事务;
- 执行 Online DDL;
- 管理统计信息、Schema 信息和部分缓存。
SQL 解析与优化
一条 SQL 进入 TiDB Server 后,大致经历:
SQL 文本
↓
Parser:解析成 AST
↓
Preprocess:语义检查、权限检查、名称绑定
↓
Logical Optimize:逻辑优化
↓
Physical Optimize:物理计划选择
↓
Executor / DistSQL:执行计划
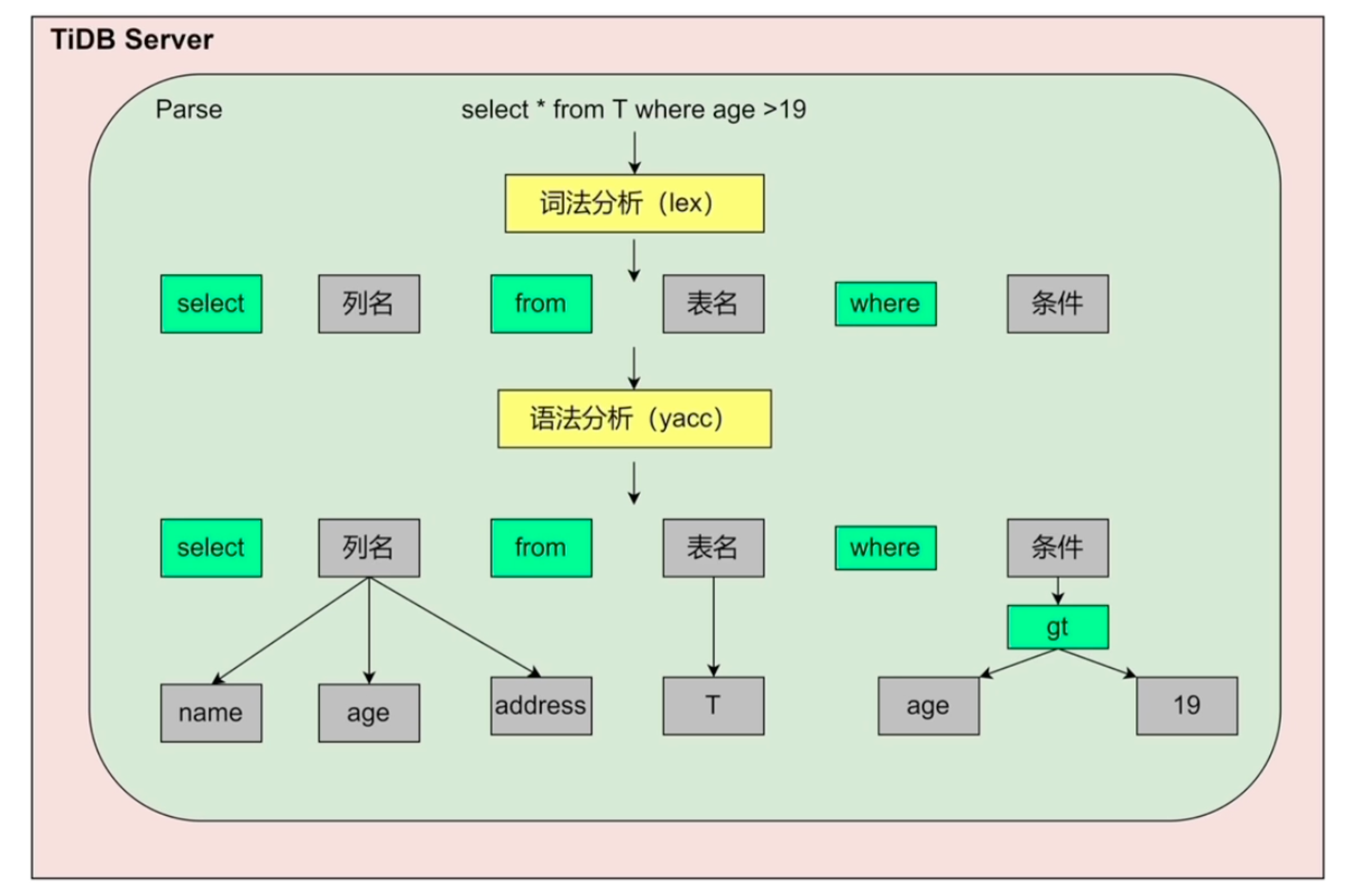
优化器会根据统计信息、索引、代价模型等信息选择执行方式。对于能下推的部分,例如 TableScan、IndexScan、Selection、Aggregation、Limit 等,TiDB 会尽量下推到 TiKV / TiFlash,以减少网络传输和 TiDB Server 端计算压力。
DistSQL 与执行位置
TiDB 的执行计划通常可以分成两类任务:
- Root Task:在 TiDB Server 执行;
- Cop Task:下推到 TiKV / TiFlash 执行。
例如简单点查可能走 KV 请求;范围扫描、过滤、聚合等可能被拆成多个 Coprocessor 任务并行下发到存储节点。
这也是 TiDB 和单机 MySQL 的重要区别:SQL 入口看起来是一个逻辑数据库,实际执行却会被拆成分布式任务。
表数据如何映射为 KV
TiDB 底层是分布式 KV 存储。关系型表中的行、索引,最终都会编码成 Key-Value。
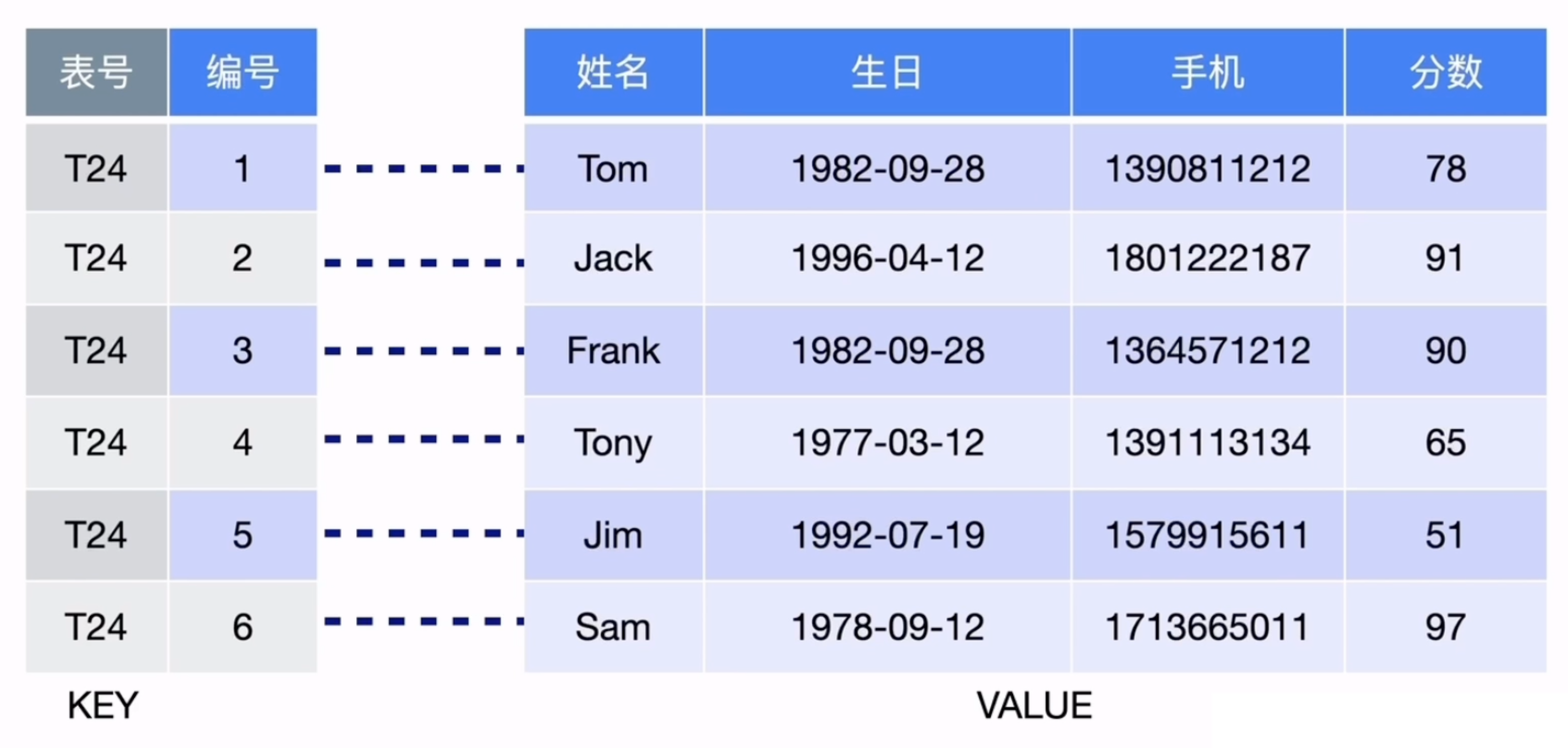
常见行数据 Key 形式可以理解为:
tablePrefix{tableID}_recordPrefixSep{rowID}
索引数据也会编码成另一类 Key。这样 TiDB 就可以把表数据和索引数据统一存储在 TiKV 的有序 KV 空间中。
聚簇索引与 _tidb_rowid
TiDB 支持聚簇索引和非聚簇索引,不同表结构会影响一行数据在 KV 层的编码方式。
| 场景 | 行数据 Key | 特点 |
|---|---|---|
| 聚簇索引表 | 主键直接参与行数据 Key 编码 | 主键就是行的物理组织依据 |
| 非聚簇索引表 | 隐式或显式 RowID 作为行数据 Key | 主键作为额外索引存在 |
| 无显式主键 | TiDB 生成 _tidb_rowid |
用隐式 RowID 定位行 |
简单理解:
- 聚簇索引:主键就是行数据的定位方式;
- 非聚簇索引:行数据由
_tidb_rowid定位,主键或二级索引再指向行数据; - 如果没有合适主键,TiDB 会使用隐式
_tidb_rowid。
这部分可以类比 MySQL InnoDB 的聚簇索引理解,但 TiDB 的底层不是 B+ 树页,而是分布式有序 KV。关于 B+ 树与 InnoDB 索引,可以参考:B+树原理与 MySQL InnoDB 索引机制解析。
Region:TiDB 数据分布的基本单位
TiKV 会把整个 Key-Value 空间切分成多个连续 Key Range,每个 Range 称为一个 Region。
Region 1: [key_a, key_f)
Region 2: [key_f, key_m)
Region 3: [key_m, key_z)
Region 是 TiKV 中数据调度、复制、分裂和合并的基本单位。
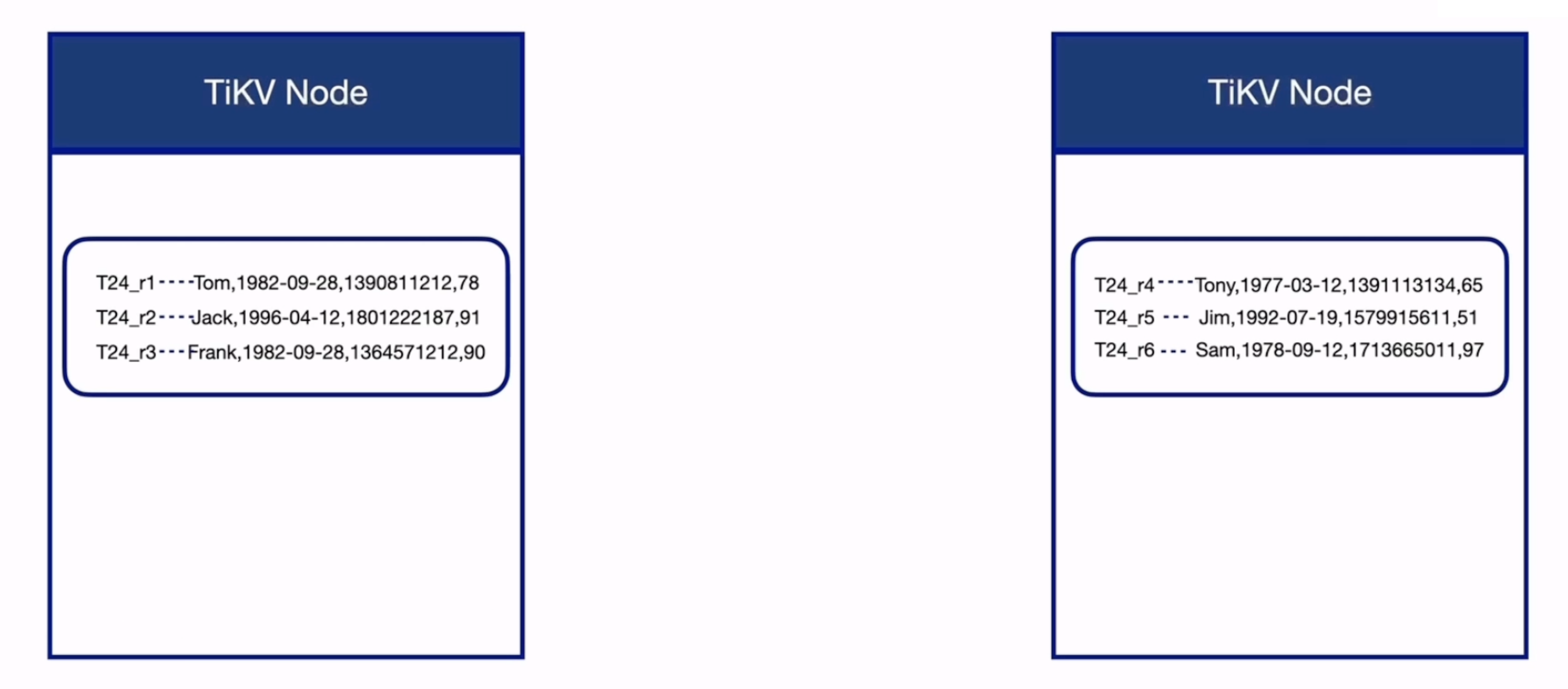
当某个 Region 变大时,会触发 Split;当 Region 太小或数据删除较多时,可能触发 Merge。旧版本资料中常见 Region 大小范围为 96 MiB~144 MiB;当前稳定版本文档中,Region 默认大小限制已经有新的配置默认值,因此实际生产应以当前 TiDB 版本配置为准。
Region 的价值在于:
- 让数据可以在多个 TiKV 节点之间均衡分布;
- 让热点 Region 可以被 PD 识别并调度;
- 让副本复制和故障恢复以较小粒度进行。
TiKV:分布式 KV 存储层
TiKV 是 TiDB 的行存储层,负责真正保存 OLTP 数据。
主要能力包括:
- 数据持久化;
- Region 管理;
- Raft 多副本一致性;
- MVCC;
- 分布式事务;
- Coprocessor 下推计算;
- RocksDB 本地存储。
RocksDB 与 LSM Tree
TiKV 底层使用 RocksDB 存储数据。RocksDB 是典型的 LSM Tree 存储引擎,写入路径通常包括:
写入 WAL
↓
写入 MemTable
↓
MemTable 变为 Immutable MemTable
↓
Flush 成 SSTable
↓
后台 Compaction
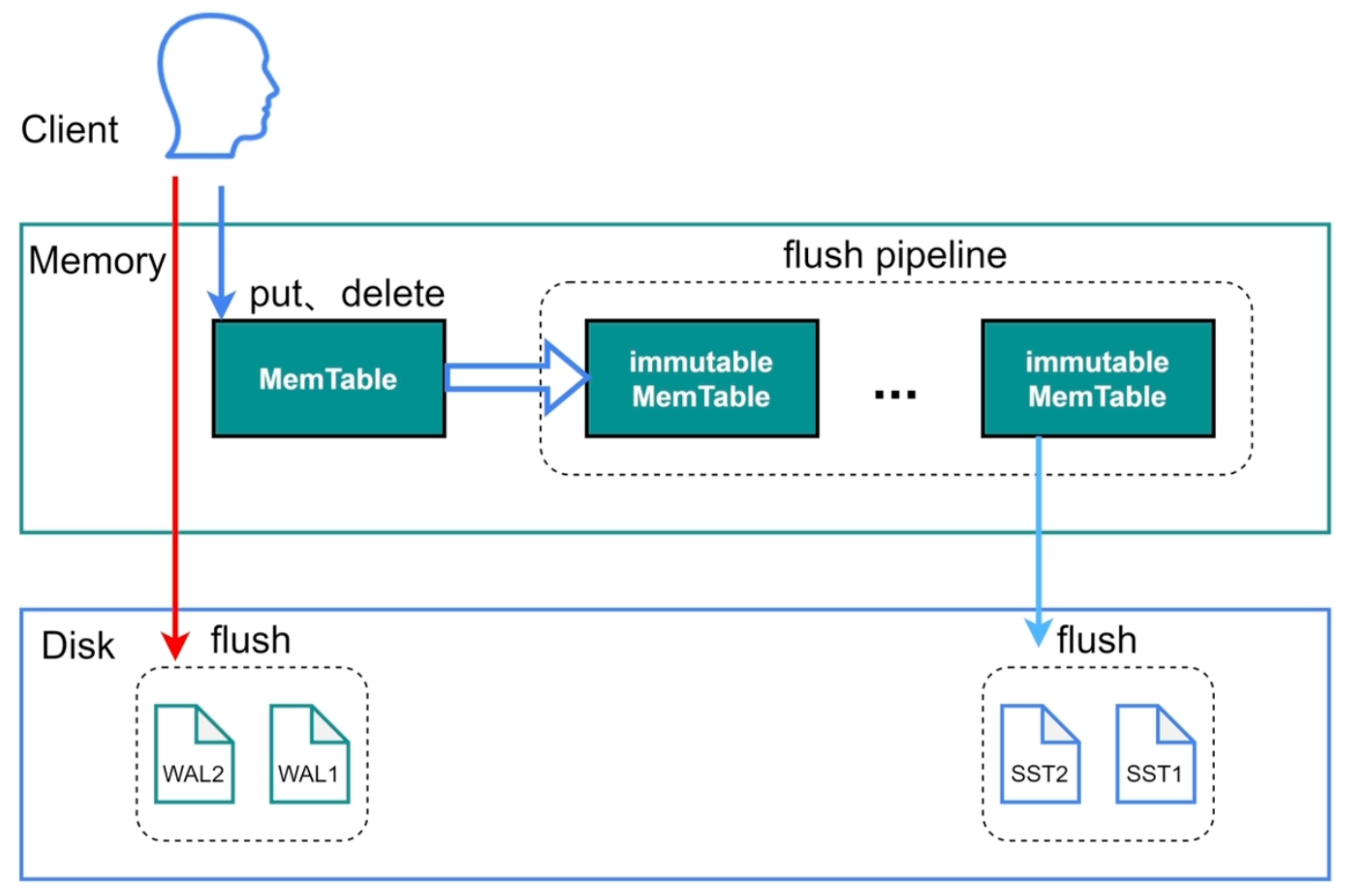
这种结构对写入友好:前台写入多为追加写和内存写,复杂的排序与合并交给后台 Compaction。
但它也会带来读放大、写放大、空间放大等问题。关于 LSM Tree 的更多细节,可以参考:LSM Tree 存储结构解析:写入密集场景下的数据组织与压缩。
Column Families
TiKV 使用 RocksDB 的 Column Family 组织不同类型的数据。事务相关数据通常会涉及:
| CF | 作用 |
|---|---|
| Default CF | 存储较大的实际数据 |
| Write CF | 存储提交记录和较小数据 |
| Lock CF | 存储事务锁信息 |
| Raft CF | 存储 Raft 日志 |
需要注意,Column Family 是 RocksDB 内部的数据组织方式,不等同于关系型数据库中的“列”。
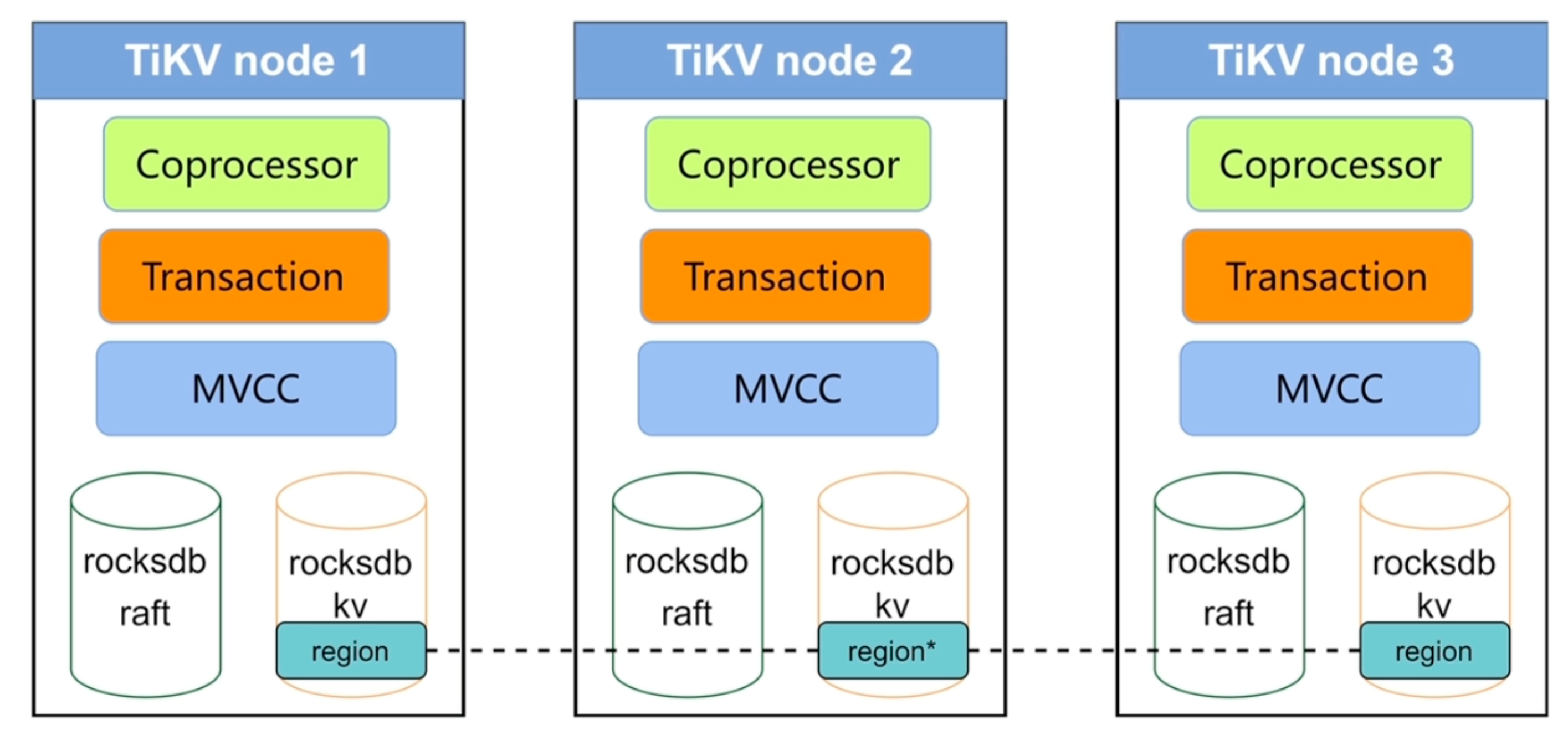
Raft:副本一致性与高可用
TiKV 通过 Raft 协议保证 Region 多副本之间的一致性。每个 Region 会有多个 Replica,分布在不同 TiKV 节点上,其中一个为 Leader,其余为 Follower。
写入通常由 Leader 接收,然后复制到 Follower。多数副本确认后,日志才算在 Raft 层提交。
Raft 日志复制流程
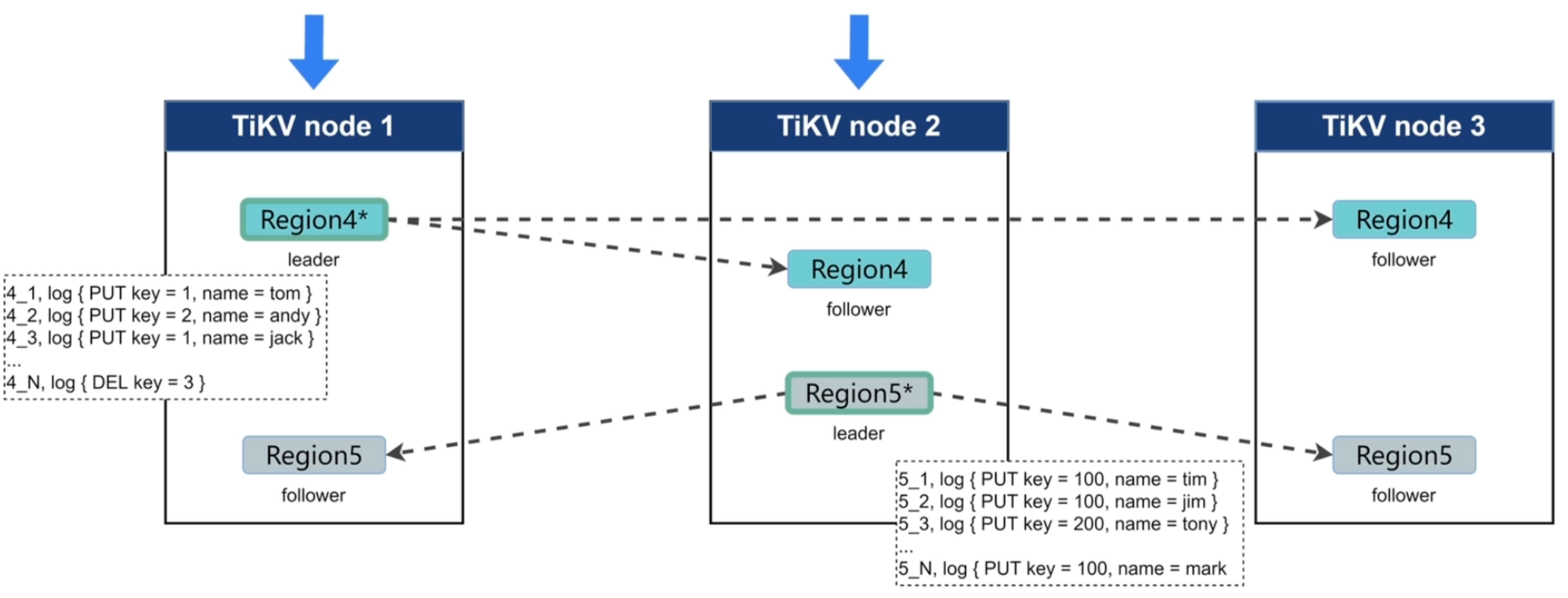
可以简化为:
Propose:TiKV 接收请求并生成 Raft 日志
↓
Append:Leader 本地持久化日志
↓
Replicate:Leader 复制日志到 Follower
↓
Committed:多数副本确认,Raft 日志提交
↓
Apply:将日志应用到 RocksDB KV
这里要区分两个“提交”:
- Raft committed:说明日志已经被多数副本确认;
- 事务 committed:说明数据库事务完成提交,对外可见。
二者属于不同层次。
Leader 选举
当 Region Leader 不可用时,Follower 会进入选举流程。节点会根据 term、日志新旧程度、投票结果等信息选出新的 Leader。
TiKV 的高可用不是依赖共享存储,而是依赖每个 Region 的多副本和 Raft 协议。
MVCC 与分布式事务
TiDB 支持分布式事务,事务模型可以从三个关键词理解:
- TSO:全局时间戳;
- MVCC:多版本并发控制;
- 2PC:两阶段提交。
MVCC:多版本并发控制
MVCC 的核心是让同一个 Key 可以存在多个版本。读请求根据自己的 start_ts 读取对应快照,写请求通过事务提交生成新的版本。
这样 TiDB 可以支持快照读,避免普通读写互相阻塞。
2PC:Prewrite 与 Commit
TiDB 的事务提交过程可以简化为:
获取 start_ts
↓
读取快照并在 memBuffer 暂存修改
↓
Prewrite:写锁和待提交数据
↓
获取 commit_ts
↓
Commit:写提交记录
↓
清理锁信息
TiDB 支持乐观事务和悲观事务。新版本集群默认通常使用悲观事务模式,更接近 MySQL 用户的使用习惯,也能降低高冲突场景下的重试成本。
Lock / Write / Default CF
事务数据在 TiKV 中会拆分到不同 CF:
- Lock CF:记录锁信息;
- Write CF:记录提交信息、较小数据或指向 Default CF 的指针;
- Default CF:保存较大 Value。
这种设计可以让 MVCC 读取和事务提交更高效。
读取路径:ReadIndex、Lease Read 与 Follower Read
TiDB / TiKV 的读取既要考虑性能,也要考虑一致性。
ReadIndex Read
ReadIndex Read 用于保证线性一致性读取。Leader 会确认自己仍然是合法 Leader,并等待本地 Apply 进度达到对应 ReadIndex 后再读取。
记录 ReadIndex
↓
等待 applyIndex >= readIndex
↓
读取本地 RocksDB 快照
Lease Read
Lease Read 也叫 Local Read。Leader 在租约有效期内可以不经过完整 ReadIndex 流程,直接在本地读取,以降低延迟。
它依赖 Leader Lease 的正确性,因此需要严格控制时钟和租约边界。
Follower Read
Follower Read 允许从 Follower 副本读取数据,从而分摊 Leader 读压力。Follower 读取前需要确认自己已经 Apply 到足够新的位置,避免读到过旧数据。
它适合读压力较大、希望提升副本利用率的场景。
PD:元数据、TSO 与调度中心
PD,全称 Placement Driver,是 TiDB 集群的大脑。
主要职责包括:
- 保存 Region 元数据;
- 维护 TiKV 节点状态;
- 分配全局 ID;
- 提供 TSO;
- 生成调度计划;
- 支持 Label 和拓扑感知;
- 提供 Dashboard 相关能力。
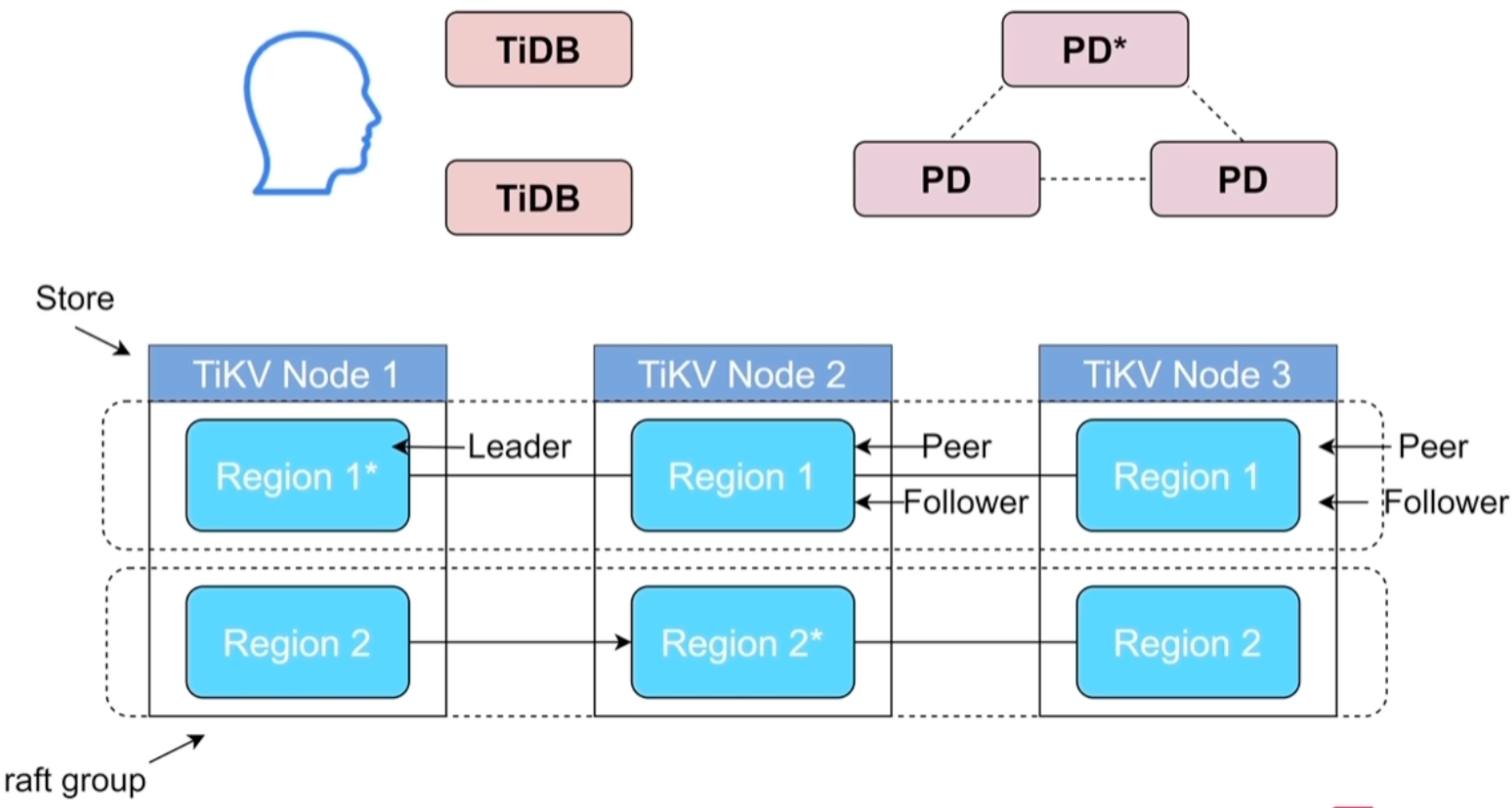
TSO:全局时间戳
TSO,全称 Timestamp Oracle,是 TiDB 分布式事务的基础。事务开始时获取 start_ts,提交时获取 commit_ts。
TSO 一般可以理解为:
physical time + logical counter
它既要保证全局单调递增,又要支持高并发分配。因此 TiDB 会通过 PD Client 批量获取和缓存 TSO,减少频繁访问 PD 的开销。
Region 调度
PD 会根据 TiKV 上报的信息进行调度,包括:
- Region 数量均衡;
- Leader 数量均衡;
- 热点 Region 调度;
- 副本补齐;
- 故障恢复;
- Region Split / Merge;
- Label 感知调度。
例如当某台 TiKV 节点磁盘压力较大,或者某个节点承载过多 Leader,PD 会生成调度计划,把部分 Region 或 Leader 迁移到其他节点。
Label 与高可用
Label 用于描述拓扑信息,例如:
zone = z1
rack = r1
host = h1
配置合理的 Label 后,PD 可以把同一个 Region 的不同副本分散到不同机架、可用区或主机上,降低单点故障风险。
TiFlash:列存与 HTAP
TiFlash 是 TiDB 的列式存储组件,主要用于 OLAP 查询加速和 HTAP 场景。
它的核心特点:
- 列式存储,适合分析查询;
- 通过 Raft Learner 从 TiKV 异步复制数据;
- 不参与 Raft 投票;
- 支持一致性读取;
- 与 TiKV 形成行存 + 列存的混合架构;
- TiDB 优化器可以根据代价选择 TiKV 或 TiFlash。
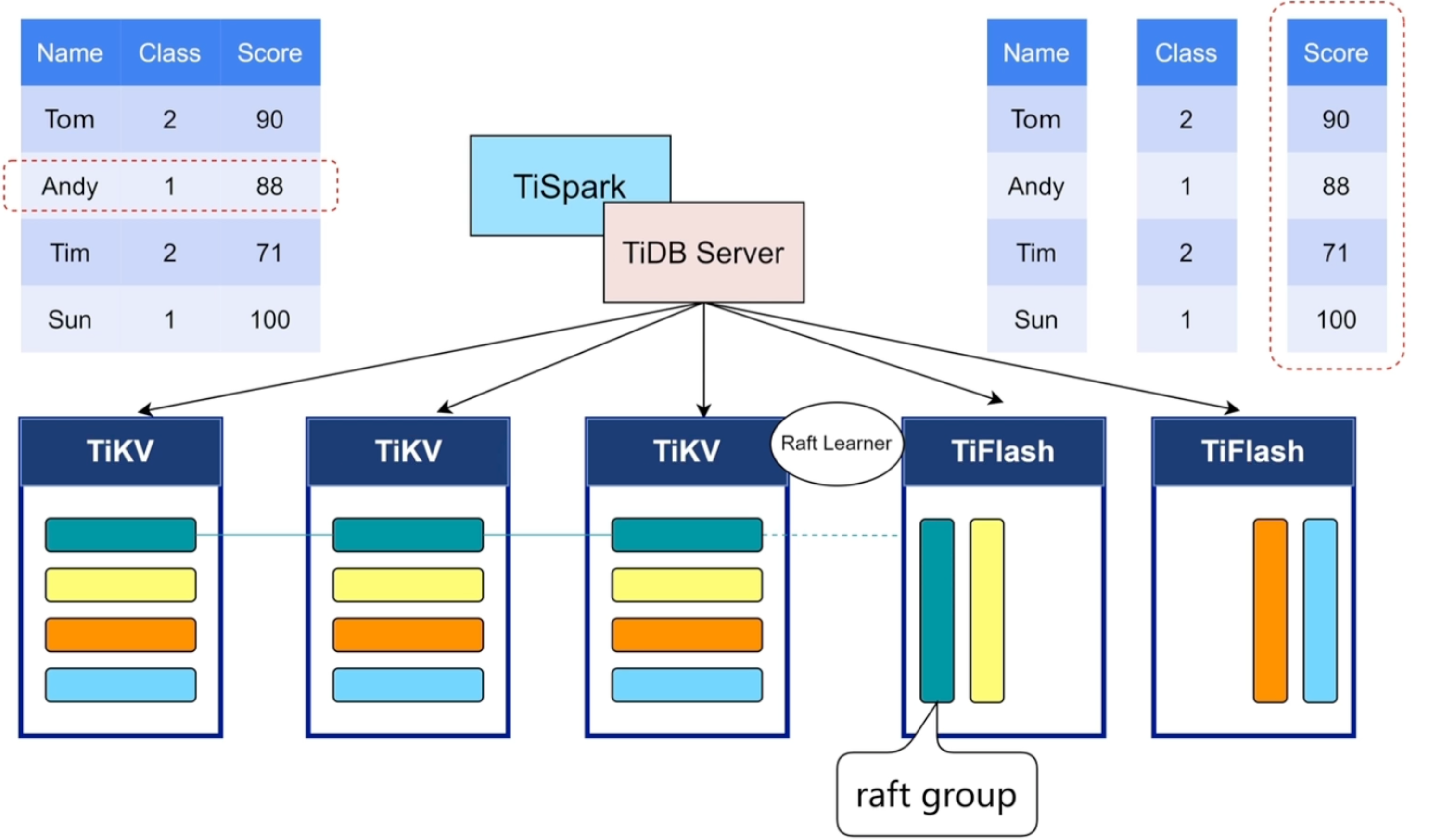
为什么 TiFlash 可以支持 HTAP?
传统架构中,OLTP 和 OLAP 往往需要两套系统:业务库负责交易,数仓或分析库负责报表,中间通过 ETL 同步。
TiDB 的 HTAP 思路是:
TiKV:行存,服务 OLTP
TiFlash:列存,服务 OLAP
Raft Learner:复制 TiKV 数据到 TiFlash
TiDB Optimizer:自动或手动选择执行引擎
这样可以减少数据同步链路,让交易数据更快进入分析查询。
Online DDL 与 Schema 变更
TiDB 支持 Online DDL,目标是在执行表结构变更时尽量不阻塞线上读写。
DDL 任务通常会进入 Job Queue,由 Owner TiDB 节点负责推进状态。Owner 不是固定机器,而是通过选举产生;如果 Owner 发生变化,新的 Owner 会继续处理 DDL Job。
对于加索引这类操作,TiDB 需要回填历史数据,因此会有专门的 Add Index 流程和后台任务。
需要注意:
Online DDL 不代表完全没有资源开销。大表加索引、列变更等操作仍然可能消耗 I/O、CPU 和网络资源,生产环境应评估执行窗口和限速策略。
GC 与历史版本清理
由于 TiDB 使用 MVCC,同一个 Key 可能存在多个历史版本。如果不清理,历史版本会持续占用空间。
GC 的作用就是清理已经不再需要的旧版本数据。
核心概念包括:
tikv_gc_life_time:历史版本保留时间;- Safe Point:早于该时间点的旧版本可以被清理;
- 长事务、备份、CDC 等任务可能影响 GC 推进。
在生产环境中,如果发现存储空间异常增长,除了业务写入量,也需要关注 GC 是否推进正常。
Cache Table:热点小表缓存
Cached Table 用于缓存访问频繁、数据量较小、更新不频繁的表。
适用场景:
- 小配置表;
- 字典表;
- 读多写少;
- 查询频繁;
- 对读延迟较敏感。
需要注意:
- 缓存表不适合频繁写入;
- 租约有效期内写入可能被阻塞;
- 对缓存表执行 DDL 前需要先取消缓存;
- 官方文档更推荐用于非常小的表,生产应结合表大小、访问频率和内存成本评估。
SQL 执行流程汇总
读流程
Client
↓
TiDB Server 接收 SQL
↓
Parser / Optimizer 生成执行计划
↓
根据 Region 路由拆分 Cop Task
↓
TiKV / TiFlash 执行下推算子
↓
TiDB 汇总结果并返回客户端
写流程
Client
↓
TiDB Server 解析并执行 DML
↓
读取需要修改的数据并写入 memBuffer
↓
事务 Prewrite
↓
Raft 复制并持久化
↓
事务 Commit
↓
返回结果
DDL 流程
Client 提交 DDL
↓
TiDB 写入 DDL Job Queue
↓
Owner TiDB 执行 DDL Job
↓
Schema 状态逐步变更
↓
必要时回填历史数据
↓
Job 进入 History Queue
TiDB 适合什么场景?
TiDB 更适合以下场景:
- MySQL 兼容需求明显:希望继续使用 MySQL 协议和生态;
- 单机 MySQL 容量或并发遇到瓶颈:需要水平扩展;
- 强一致事务要求:需要分布式事务而不是最终一致;
- 高可用要求高:希望通过多副本和自动调度减少故障影响;
- 实时 HTAP:既要交易处理,又希望对实时数据做分析;
- 海量数据在线扩缩容:希望按 Region 粒度做数据分布和调度。
但 TiDB 也不是所有场景的最优解。如果业务数据规模不大、单机 MySQL 足够支撑,或者大量依赖 MySQL 特定插件和单机特性,迁移 TiDB 前需要做充分评估。
总结
TiDB 的核心不是“一个分布式 MySQL”,而是一套完整的分布式数据库架构:
- TiDB Server 把 SQL 层做成无状态计算层;
- TiKV 把数据存储拆成 Region,并通过 Raft 实现多副本强一致;
- PD 负责元数据、TSO 和全局调度;
- TiFlash 通过列存和 Raft Learner 支撑 HTAP;
- MVCC、TSO、2PC 共同构成分布式事务基础;
- DistSQL 和 Coprocessor 让计算尽量靠近数据。
学习 TiDB 时,不要只看单个组件,而要把 SQL 层、调度层、存储层和事务层连起来理解。这样才能真正看懂 TiDB 为什么能够同时支持水平扩展、高可用、强一致事务和实时 HTAP。